https://www.youtube.com/watch?v=Ukloo2xtayQ&list=PLvbUC2Zh5oJtYXow4jawpZJ2xBel6vGhC&index=26
오승상 교수님의 심층강화학습 강의영상 DDPG을 보고 공부한 내용을 정리하였습니다.

DQN에서 discrete action space가 단점인 이유는,
로봇 팔 제어와 같은 환경에서는 continuous action space를 가질 것이다.
이것을 DQN알고리즘에 적용 시키기 위해 discrete action space로 만든다고 가정하자.
로봇의 팔이 0 ~ 180도 회전을 할 때, 0~10도 까지는 step1 ,11 ~ 20도 까지는 step2.. 등 여러개의 구간으로 쪼개서 discrete한 환경을 만들게 된다면 실제 각도는 잃어버리고, 0~10도라는 각도의 정보만을 가지게 된다.
그리고 이러한 정보는 학습 성능에 좋지 않은 영향을 줄 것이다.
DDPG에서는 DQN이 discrete action space에서만 동작했던 것을 continous action space까지 확장시킨다.

policy에는 2가지 종류가 있다.
Stochastic policy는 현재 state s에서 취할 수 있는 모든 action에 대한 확률분포를 의미하고, policy gradient algo에서는 모두 이 policy를 사용해서 개선하고 업데이트를 진행했다.
Deterministic policy는 현재 state s에서 취할 수 있는 하나의 action을 의미한다.
DDPG에서는 Deterministic policy를 사용해 actor network로 학습한다.

DQN은 off-policy learning 으로 전체 모든 action 들 중에서 Q값을 최대화 하는 action을 선택한다.
DDPG도 마찬가지로 off-policy learning을 이용하므로 DQN의 재현버퍼와 target Network를 적용한다.
재현버퍼를 사용하는 이유는
off-policy learning에서 발생하는 time corr때문에 과거의 경험들로 부터 미니배치 데이터를 샘플링해서 사용한다. 임의로 샘플링하면서 신경망이 업데이트 될 때, 낮은 분산을 가질 확률을 증가시킨다. 에이전트가 학습이 발산될 위험을 낮추어 준다.
또한 IID 가정이 성립한다.
샘플을 여러 경로와 정책에서 한 번 추출 했기 때문에, 독립적이면서 동일한 분포를 띄게된다.
미니배치데이터는 재현 버퍼에서 동일한 확률로 랜덤 추출을 진행한다.

Critic network update는
target critic network Q값과 behavior critic network Q값의 차이의 state에 대한 expectation 값이 최소화 되도록 target critic parameter를 업데이트 한다.
target critic network(Q_^_pi_^)은 target actor network에서 계산한 deterministic policy를 입력으로 받는다.

Actor network update는
behavior actor network의 Q값을 s에대한 expectation 값을 최대화하는 방향으로 진행한다.
최적화하는 과정이 짧게 축약되어있는데 증명은 더 찾아서 첨부해야겠다.
결국 Actor network는 Deterministic policy mu를 update한다.

위의 이유로 DDPG에서는
1. Deterministic policy의 출력으로 나온 action에 noise를 추가하는 방법
2. actor network에서 학습 진행 중인 파라미터 (behavior actor parameters) 에 noise를 추가하는 방법이 있다.
이때 noise는 가우시안 노이즈가 아니라 Ornstein-Unlenbeck process에서 생성되는 노이즈를 추가한다.(지도 교수님 피셜)
https://en.wikipedia.org/wiki/Ornstein%E2%80%93Uhlenbeck_process
Ornstein–Uhlenbeck process - Wikipedia
From Wikipedia, the free encyclopedia Stochastic process modeling random walk with friction Five simulations with θ = 1, σ = 1 and μ = 0. A 3D simulation with θ = 1, σ = 3, μ = (0, 0, 0) and the initial position (10, 10, 10). In mathematics, the Orns
en.wikipedia.org
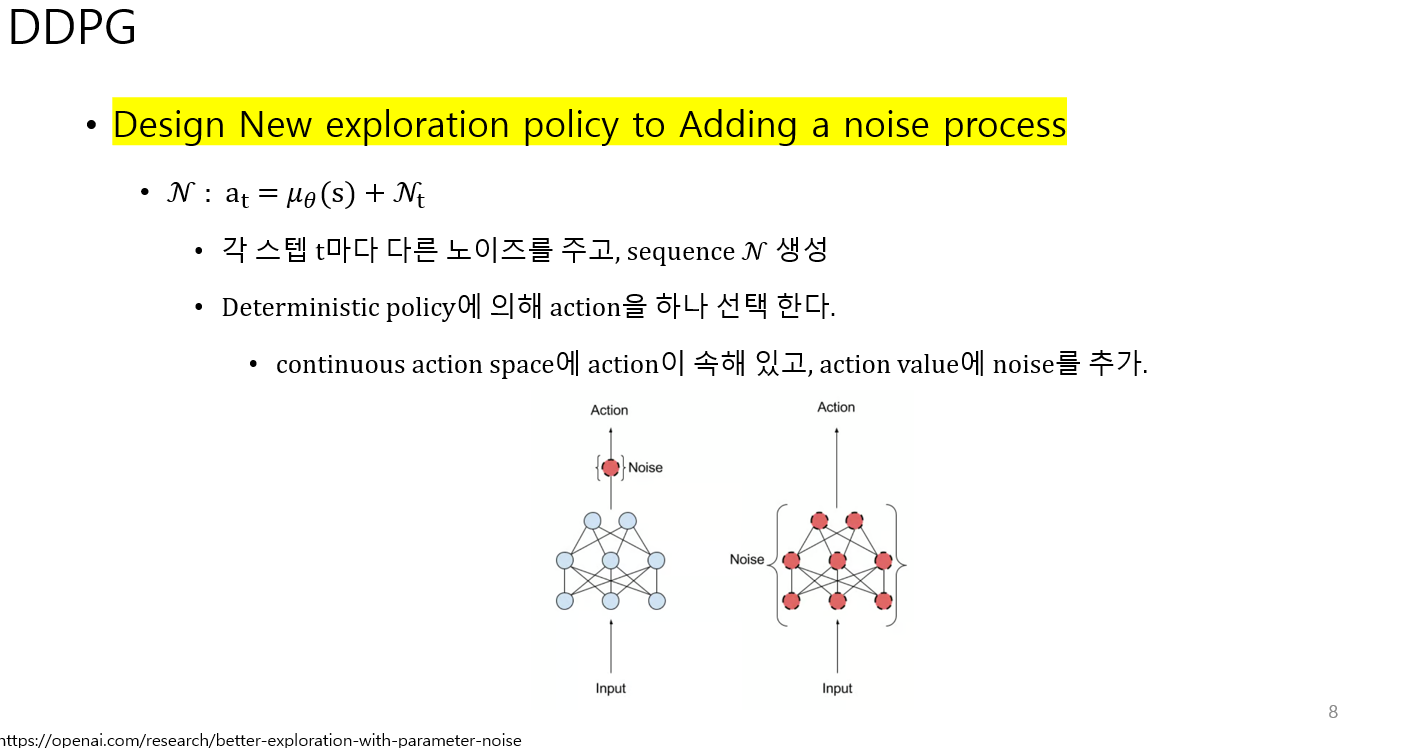
openai의 리포트에 있는 이미지를 참고했다
https://openai.com/research/better-exploration-with-parameter-noise
Better exploration with parameter noise
We’ve found that adding adaptive noise to the parameters of reinforcement learning algorithms frequently boosts performance. This exploration method is simple to implement and very rarely decreases performance, so it’s worth trying on any problem.
openai.com

DDPG w parameter noise : deterministic policy를 학습 중인 파라미터에( behavior actor parameters )noise를 더한 후에 action을 출력
성능이 가장 좋음!


'인공지능 > 강화학습' 카테고리의 다른 글
| [그로킹 심층 강화학습] - ch3. 순간 목표와 장기 목표 간의 균형(벨만 기대 방정식, 벨만 최적 방정식) (3) | 2024.02.08 |
|---|---|
| [그로킹 심층 강화학습] - ch1 심층 강화학습의 기초, ch2 강화학습의 수학적 기초 (4) | 2024.01.12 |

