https://www.yes24.com/Product/Goods/103984186
그로킹 심층 강화학습 - 예스24
사람처럼 학습하는 인공지능, 심층 강화학습의 모든 것사람은 시행착오를 통해 학습한다. 아픈 실패를 안겨준 상황을 피하고, 즐거웠던 성공의 경험을 되풀이하려 한다. 심층 강화학습도 마찬
www.yes24.com
위의 책으로 공부를 진행중입니다.
의외에 사용한 자료는 출처 남기도록 하겠습니다!
아래 이미지는 제가 공부하면서 정리한 ppt 입니다.

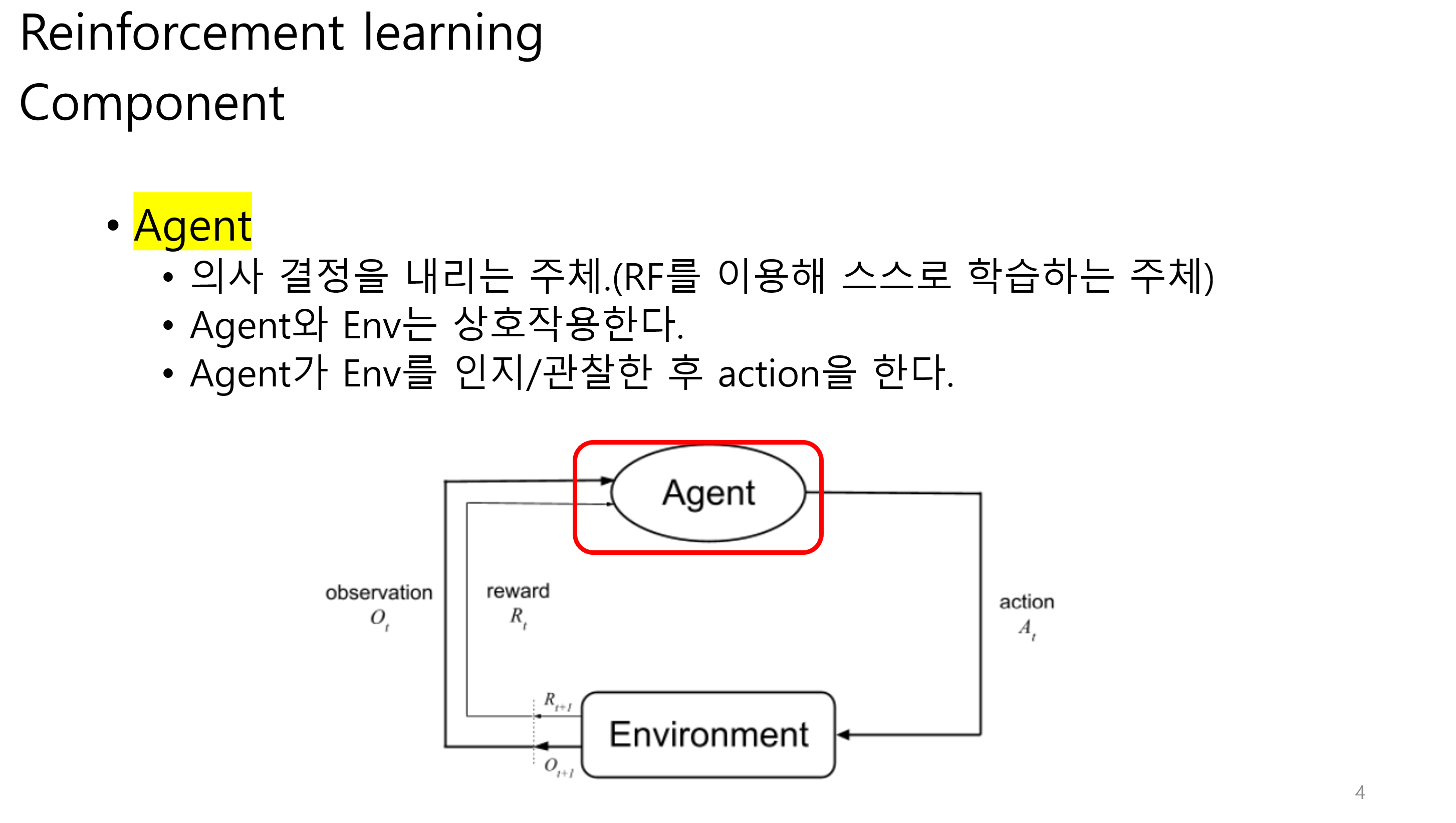
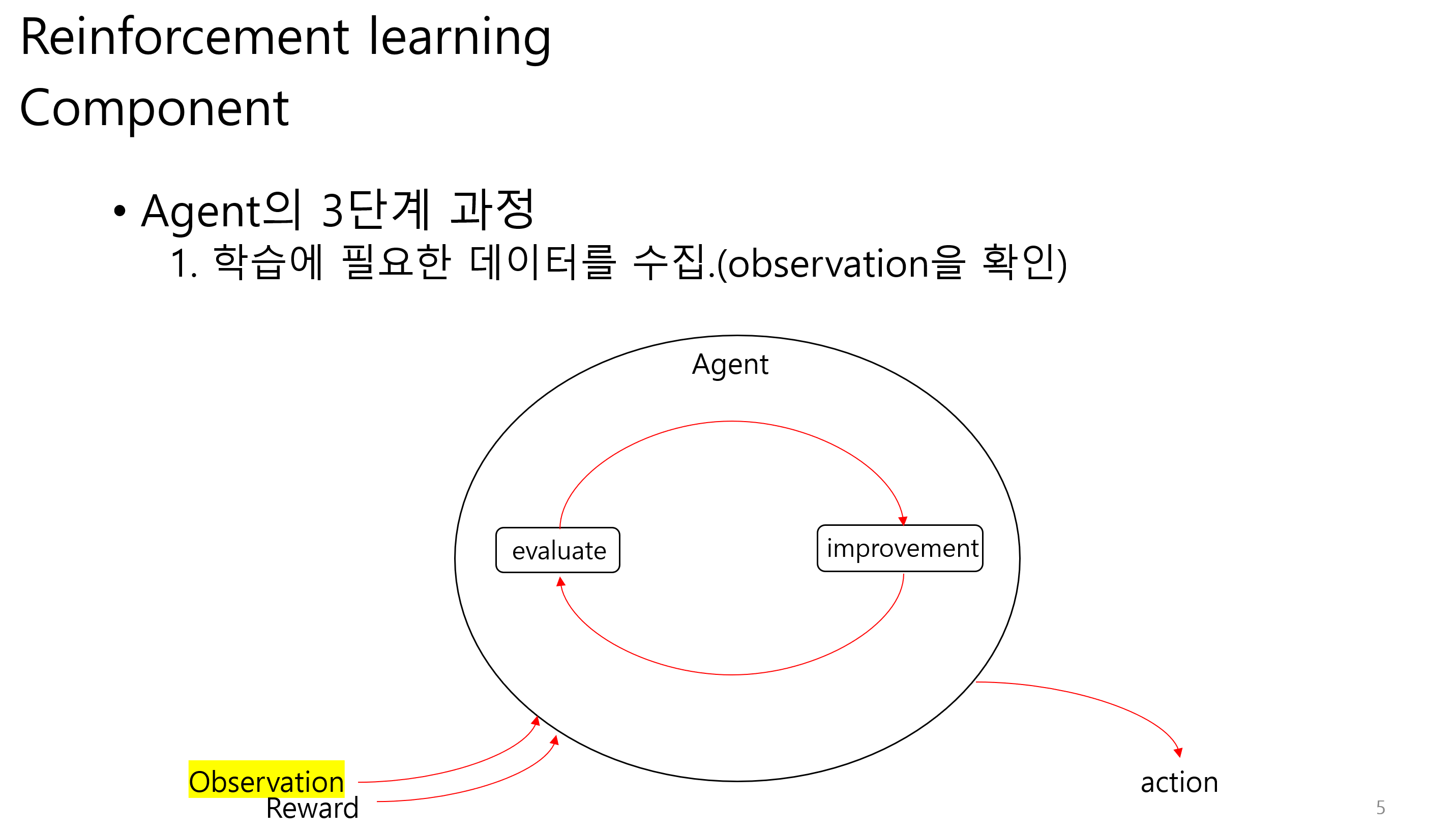
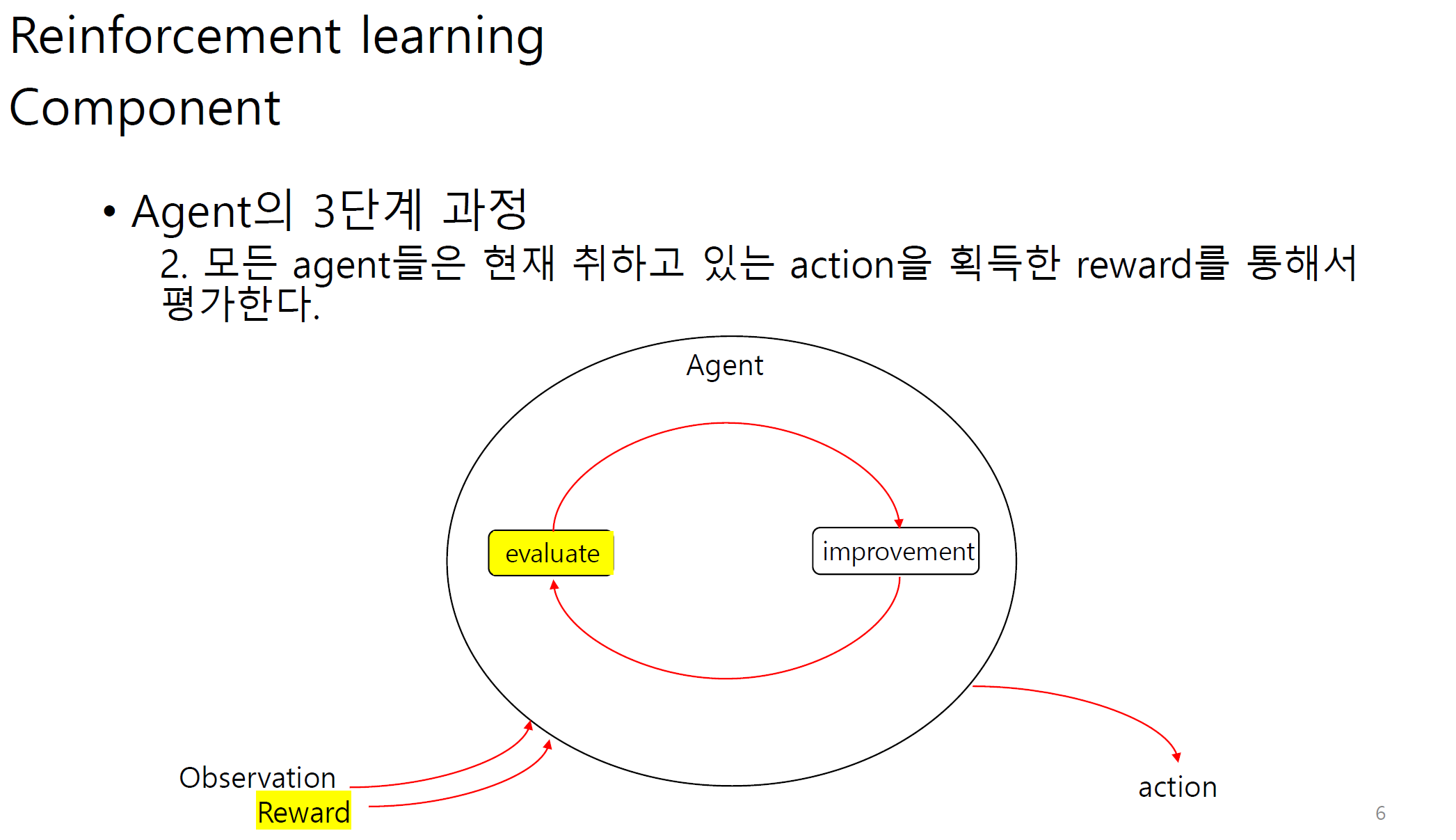
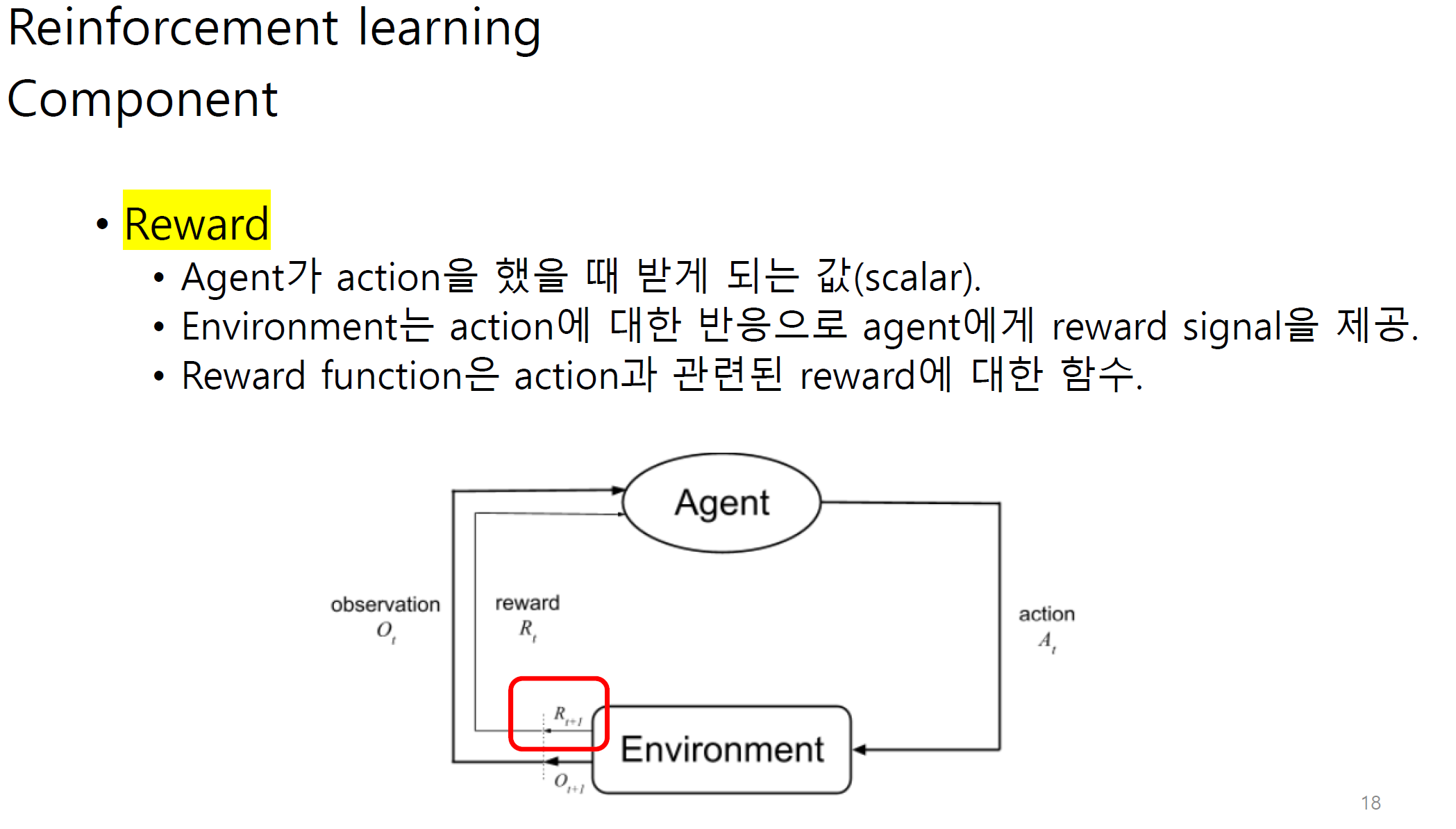
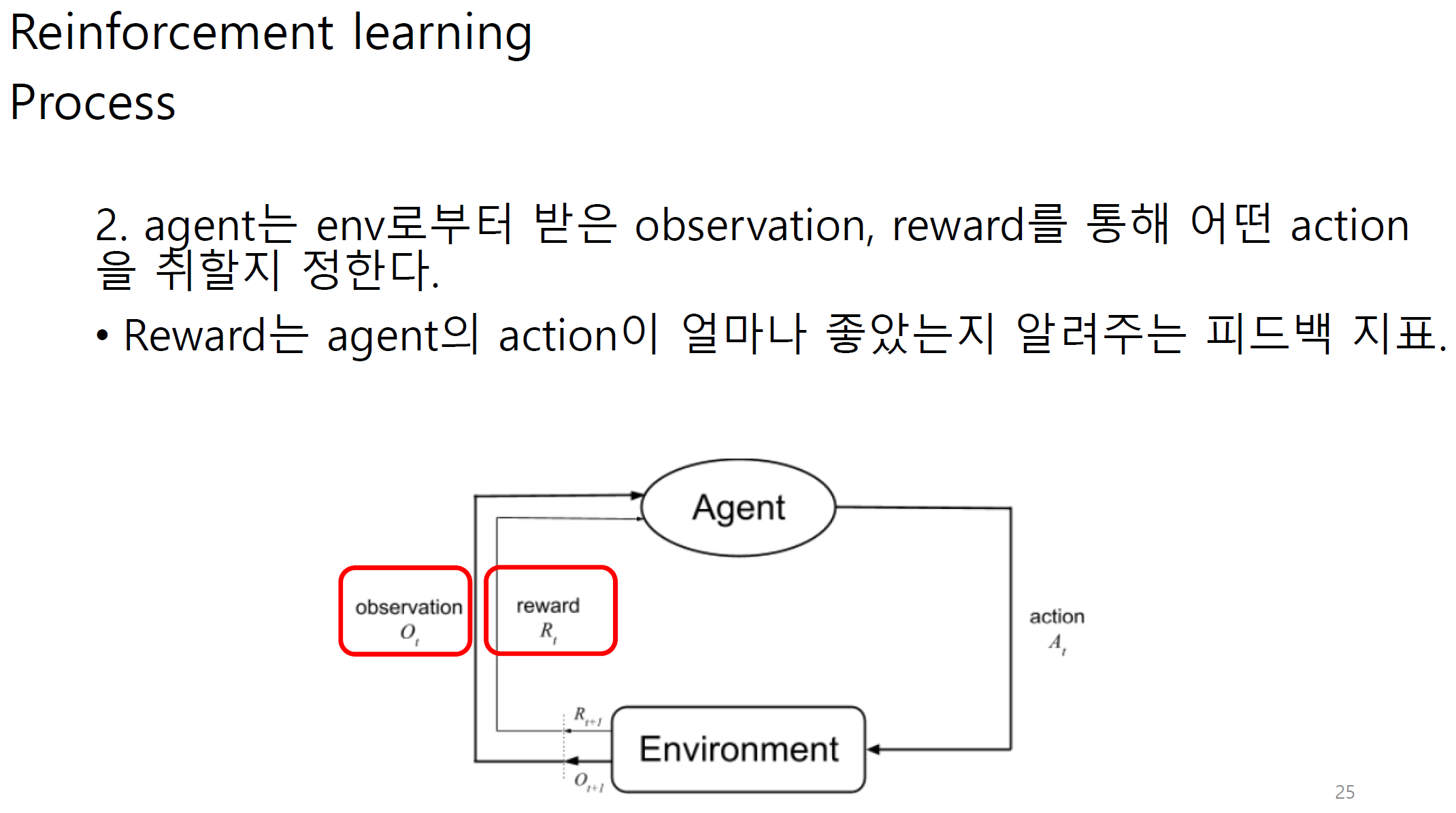
Observation에는 state와 reward가 포함된다.
그림 상에서는 다르게 나오지만 reward 또한 observation으로 볼 수 있다.
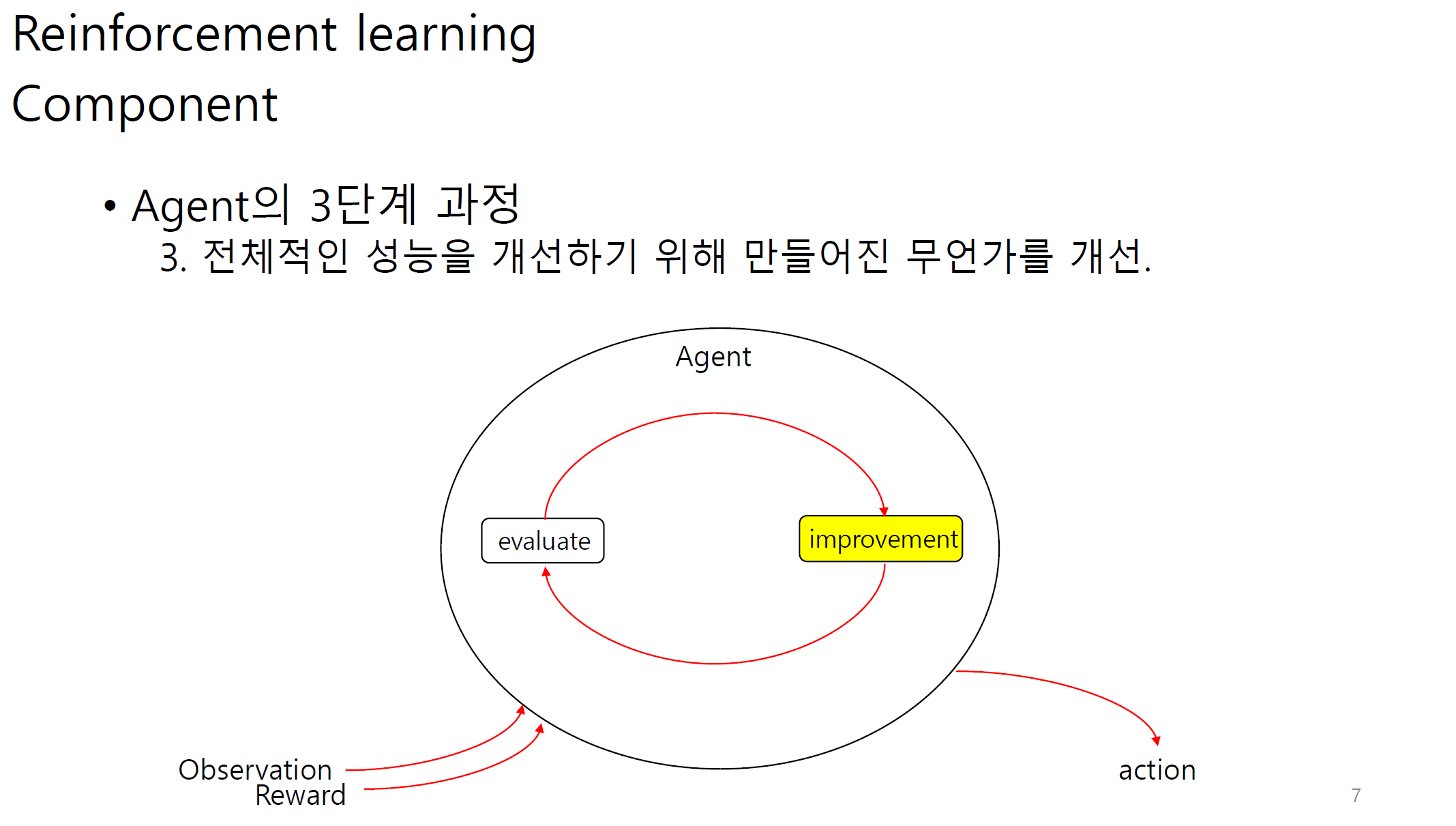

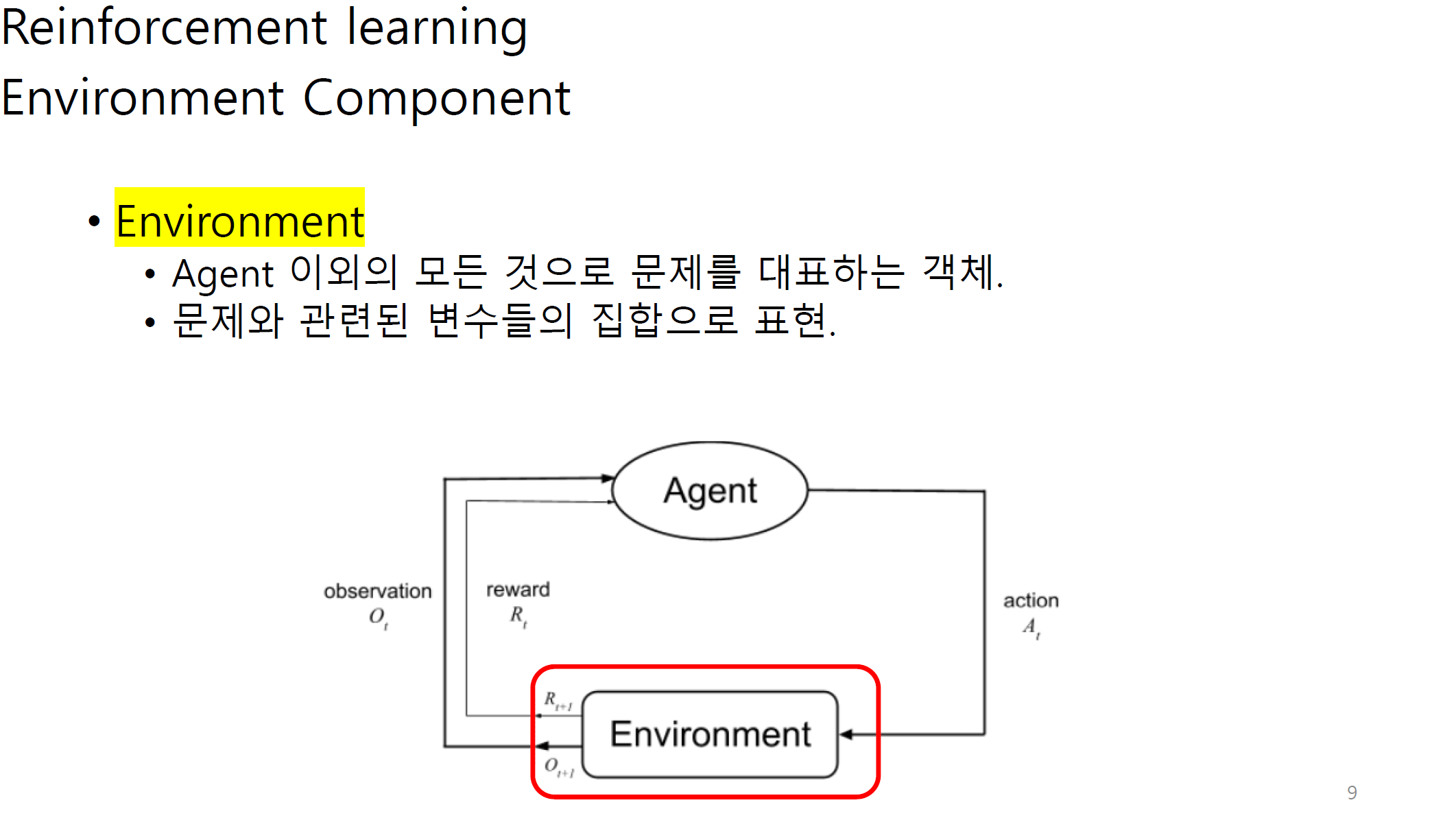
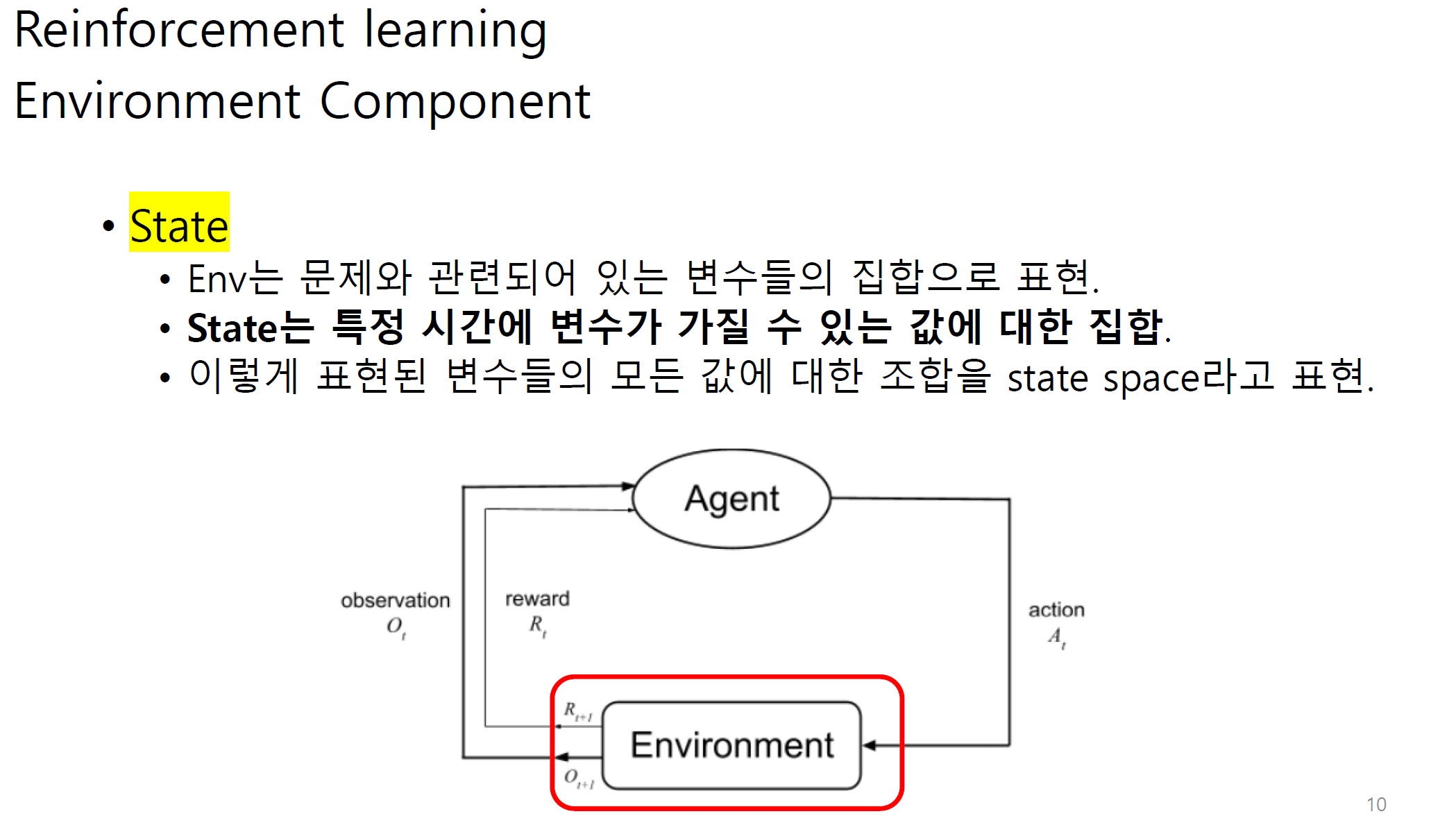
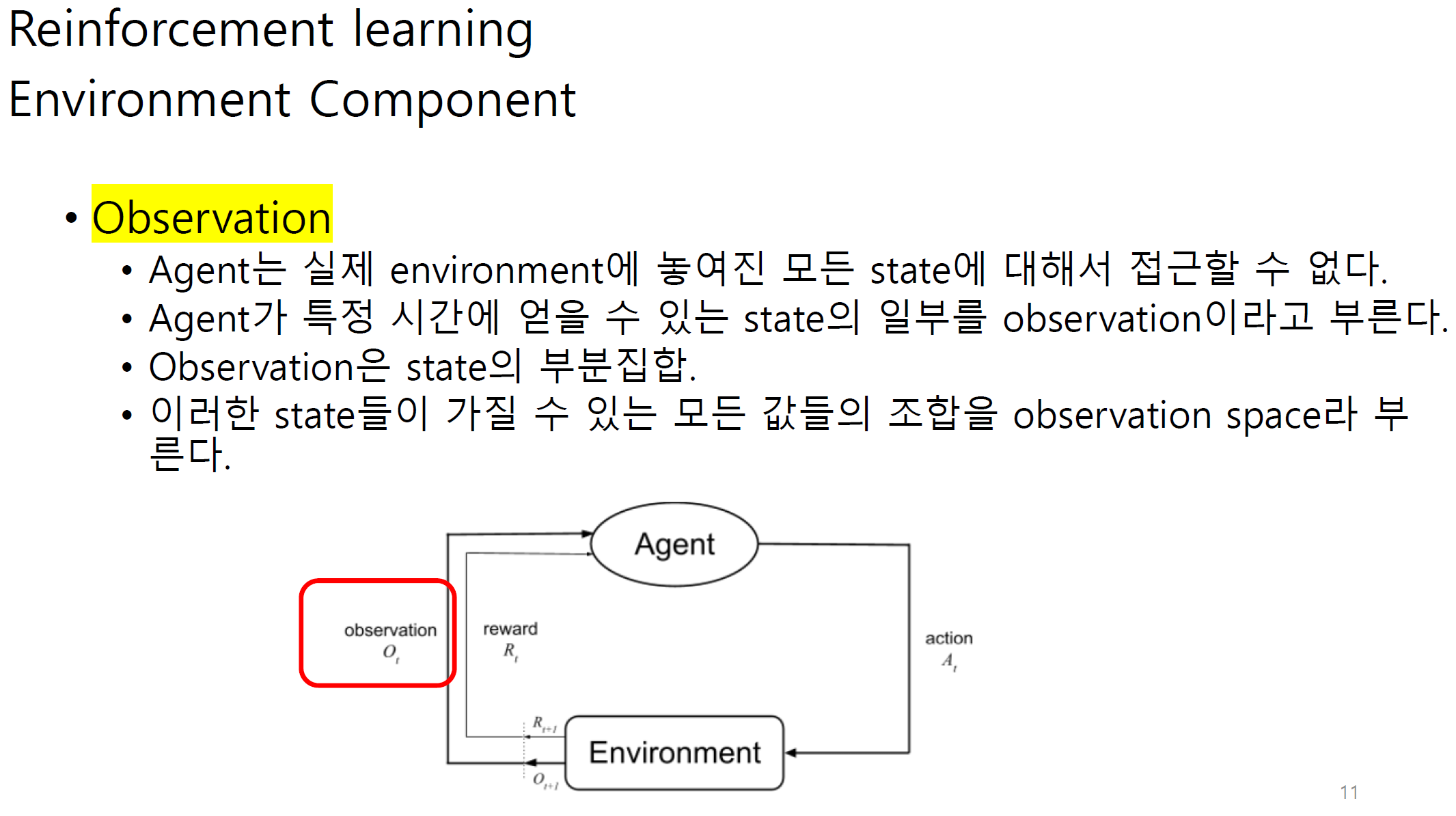


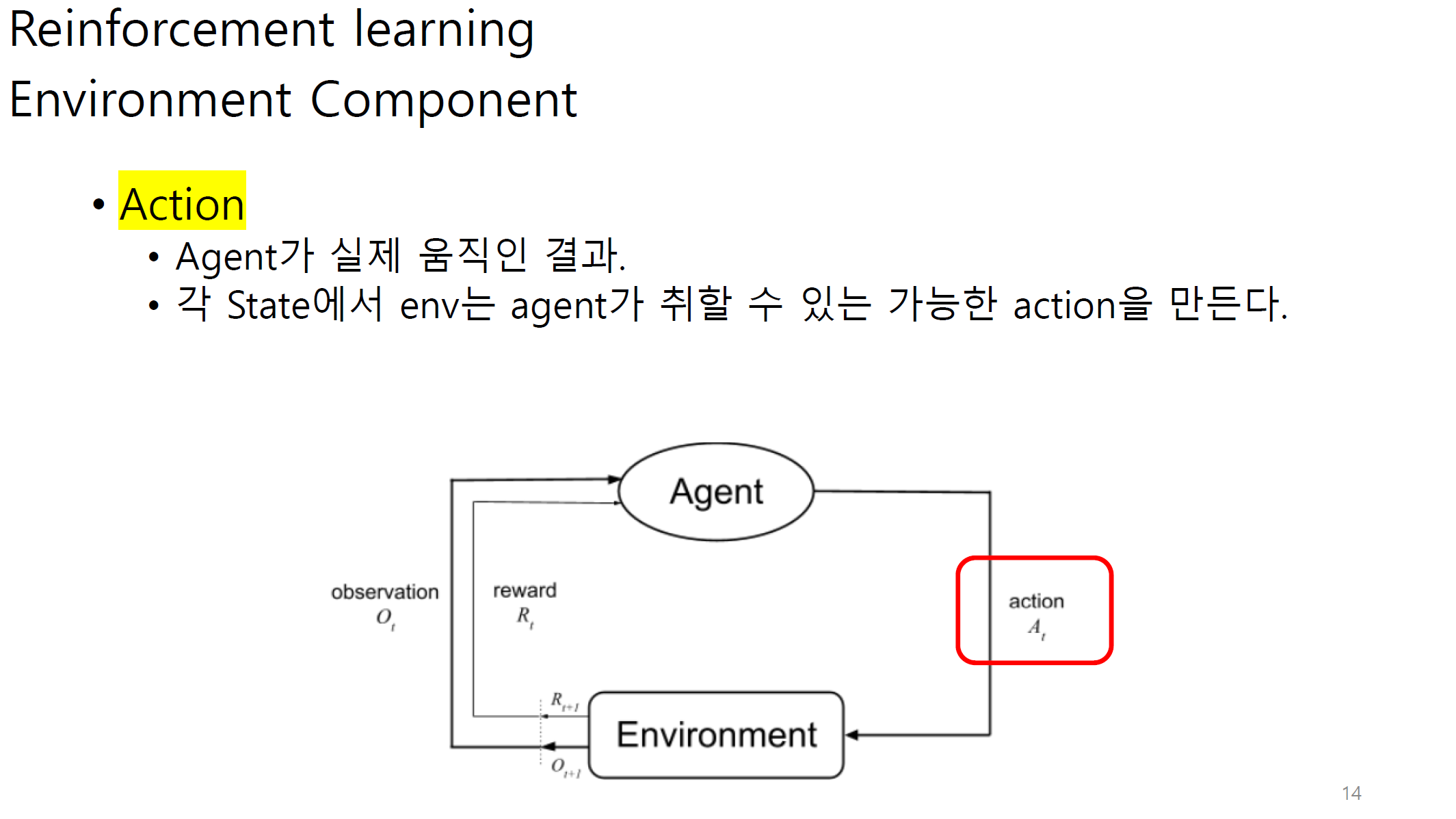

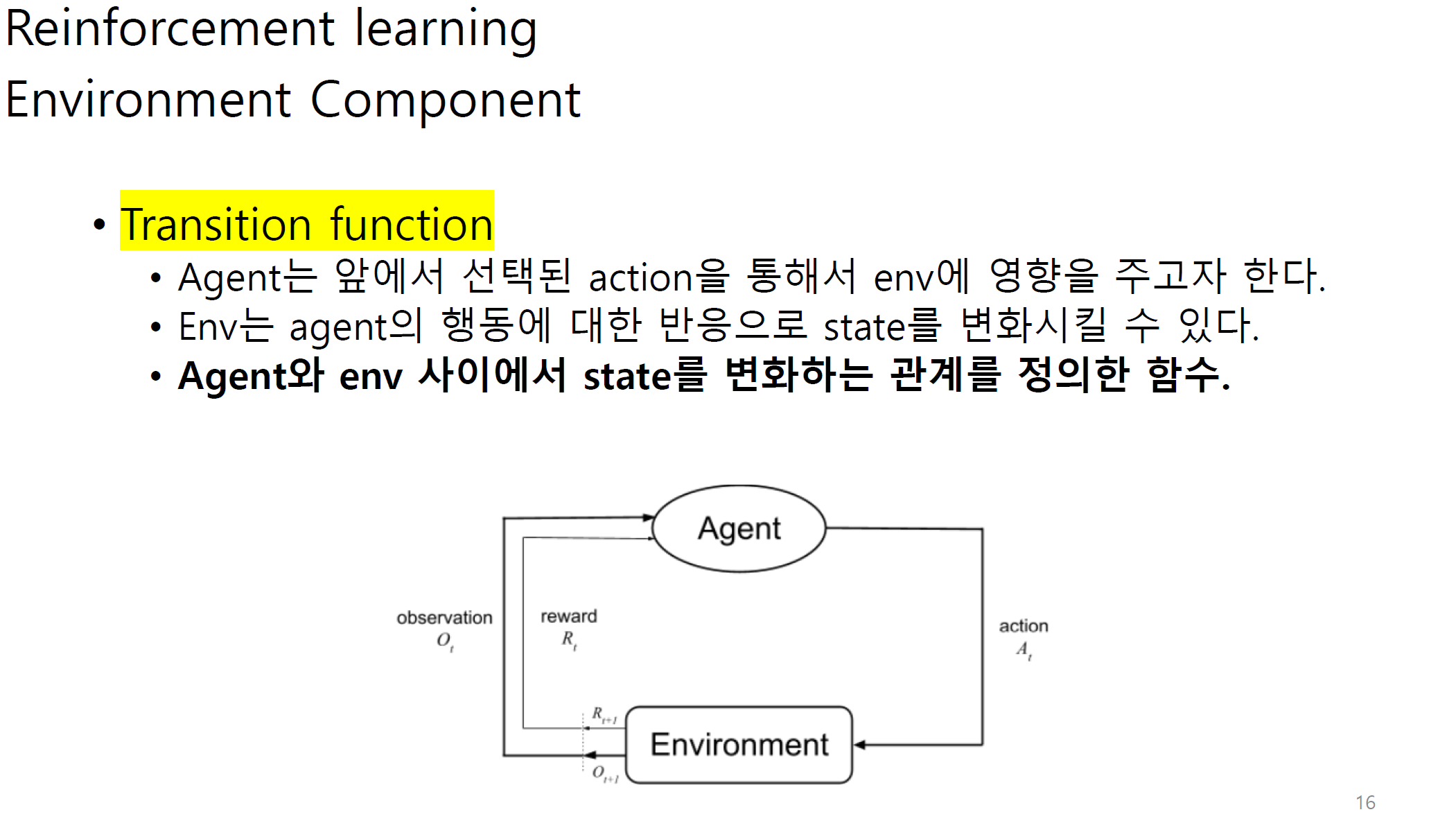
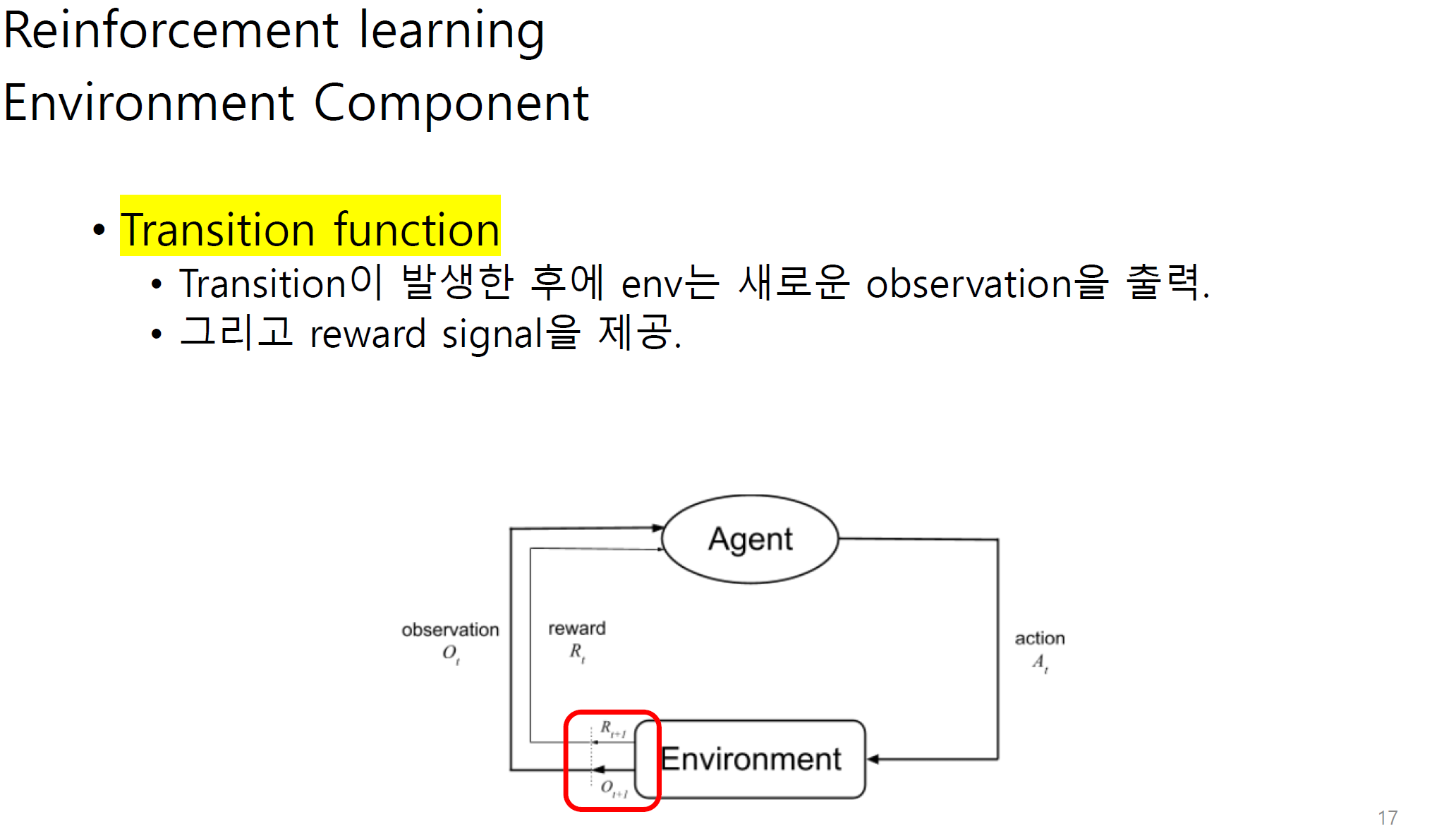
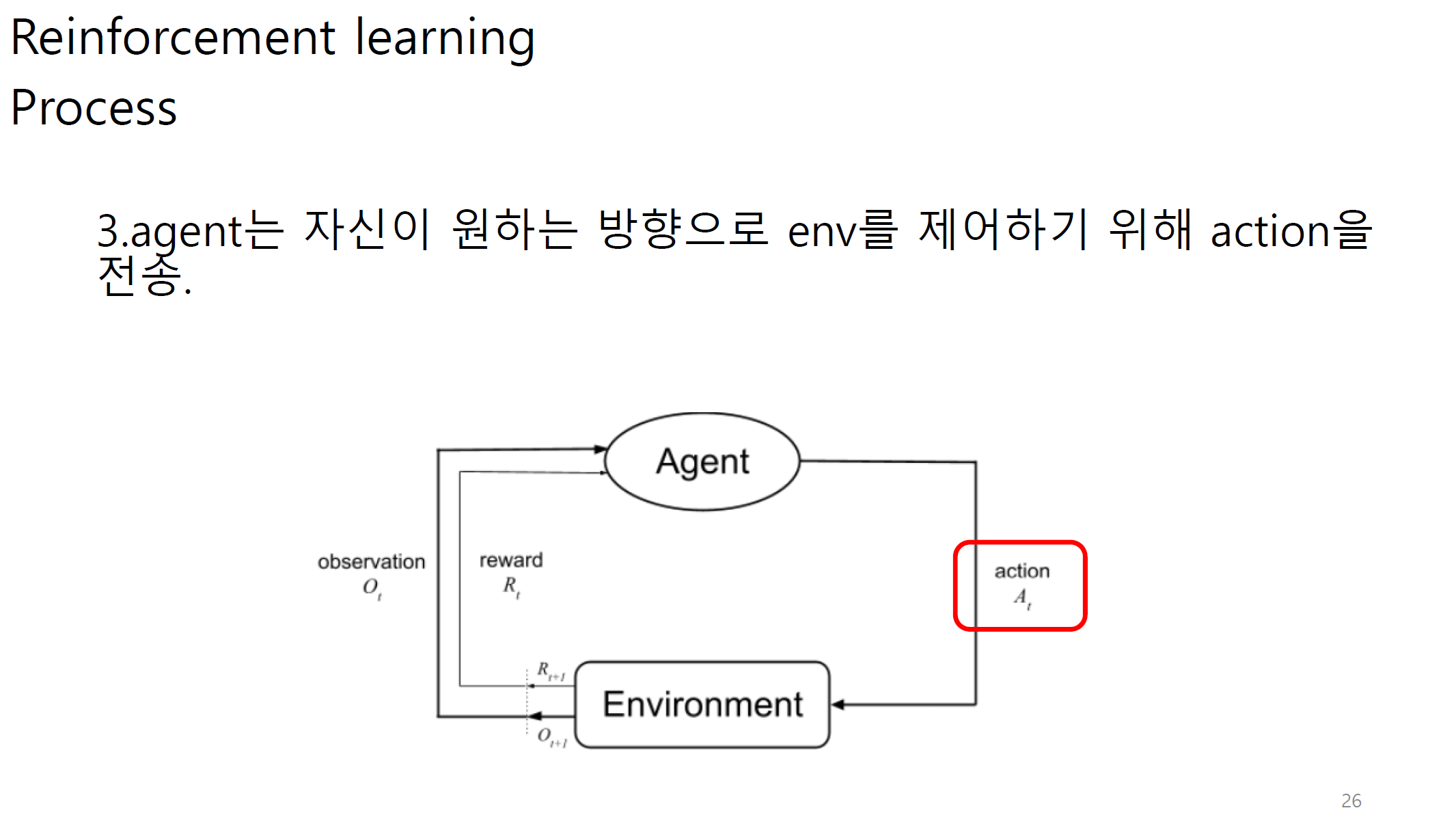
transition은 agent와 env사이에서 state가 어느정도 변화하는지에 대한 정도이다.



policy는 결국 action이다.

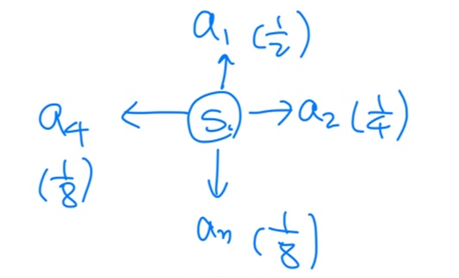

state s1에서 취할 수 있는 action이 a1,a2,a3,a4 이고 각각으로 갈 확률은 위에 그림에 나와있는 것처럼이라고 가정.
이때 value function의 출력값은 state s1에서 모든 action을 취했을 때 받을 수 있는 reward들의 기댓값이다.
위의 그림에서 수식은 vpi(s)가 아니라 vpi(s1) 이다.
value function의 수식을 보면 action이 없는데 어떻게 action을 고려할 수 있는가?
기댓값이 pi에 걸려있다. pi는 policy로 즉 action을 의미하게 되는데,
action에 대한 기댓값이 아닌, state s1이 주어졌을 때 각 action을 취했을 때 얻은 reward들을 가지고 기댓값을 계산한다.

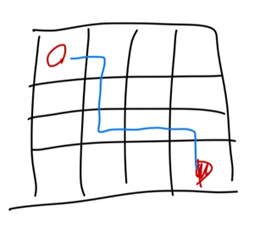
시작 state에서 터미널 state까지의 경로를 에피소드라고 한다.
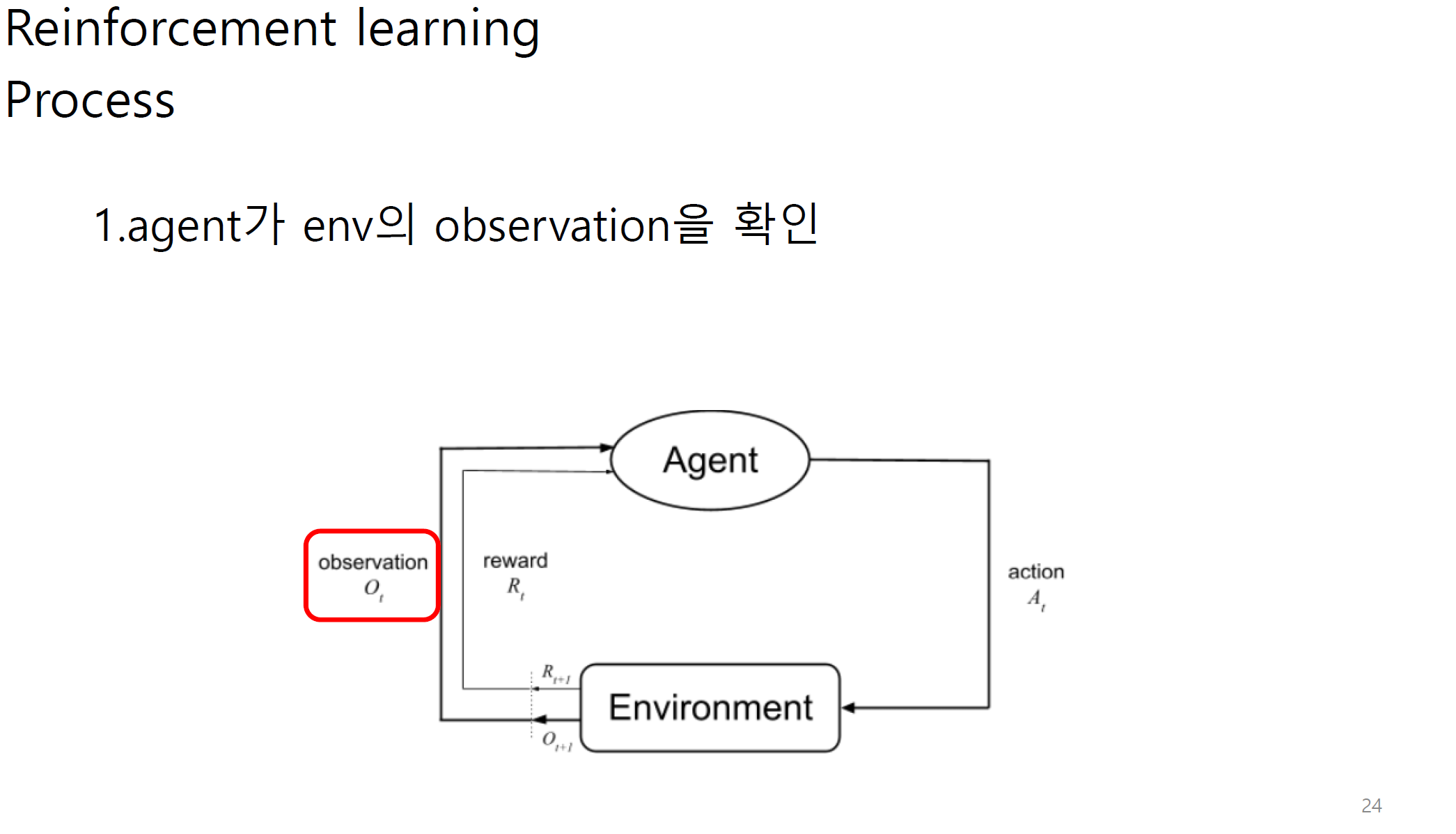




실제 강화학습을 사용하는 알고리즘에서는
처음 학습할 때는 exploration을 하고 어느 정도 학습이 되면 exploitation으로 조절한다고 한다.

여기서 샘플링된 피드백이란.
하나의 에피소드를 통해서 얻은 reward들을 의미한다.
학습을 계속해서 진행하게 되면 에피소드가 쌓이게 된다. 이것을 가지고 학습을 진행하게 된다.







MDP에서 P가 없다고 가정한다면 이것이 바로 강화학습이다.
다른 단어로는 model-free이고, 뒷장에서 더 자세하게 설명하겠다.

P 분포가 고정이라는 것은 무슨 의미일까?
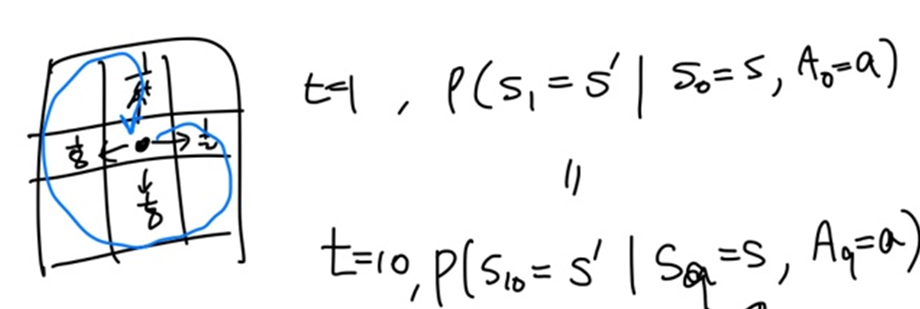
격자에서 가운데 점을 state s'이라고 하자.
time step 0에서 state s와 action a를 취했을 때
그 다음 time step 1에서 s' state로 갈 확률과
time step 9에서 state s와 action a를 취했을 때
그 다음 time step 10에서 s' state로 갈 확률이 같다는 의미이다.
즉. 학습을 하면서 다시 같은 state로 올 확률은 고정되어야 한다는 의미.
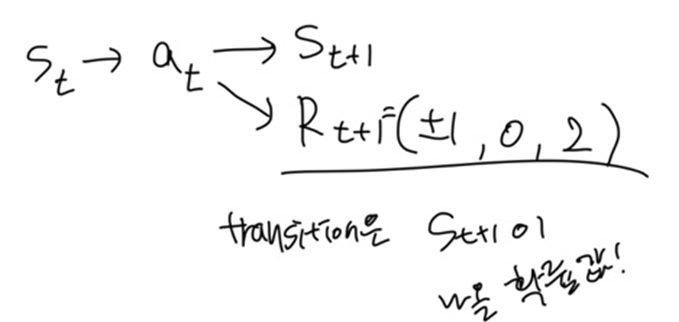
time step t에서 state s_t 가 action a를 취했을 때,
다음 time step인 t+1에서 state s_t+1이 나올 확률이 transition이다.
위에서 설명했듯이
transition은 agent와 env사이에서 state가 어느정도 변화하는지에 대한 정도이다.
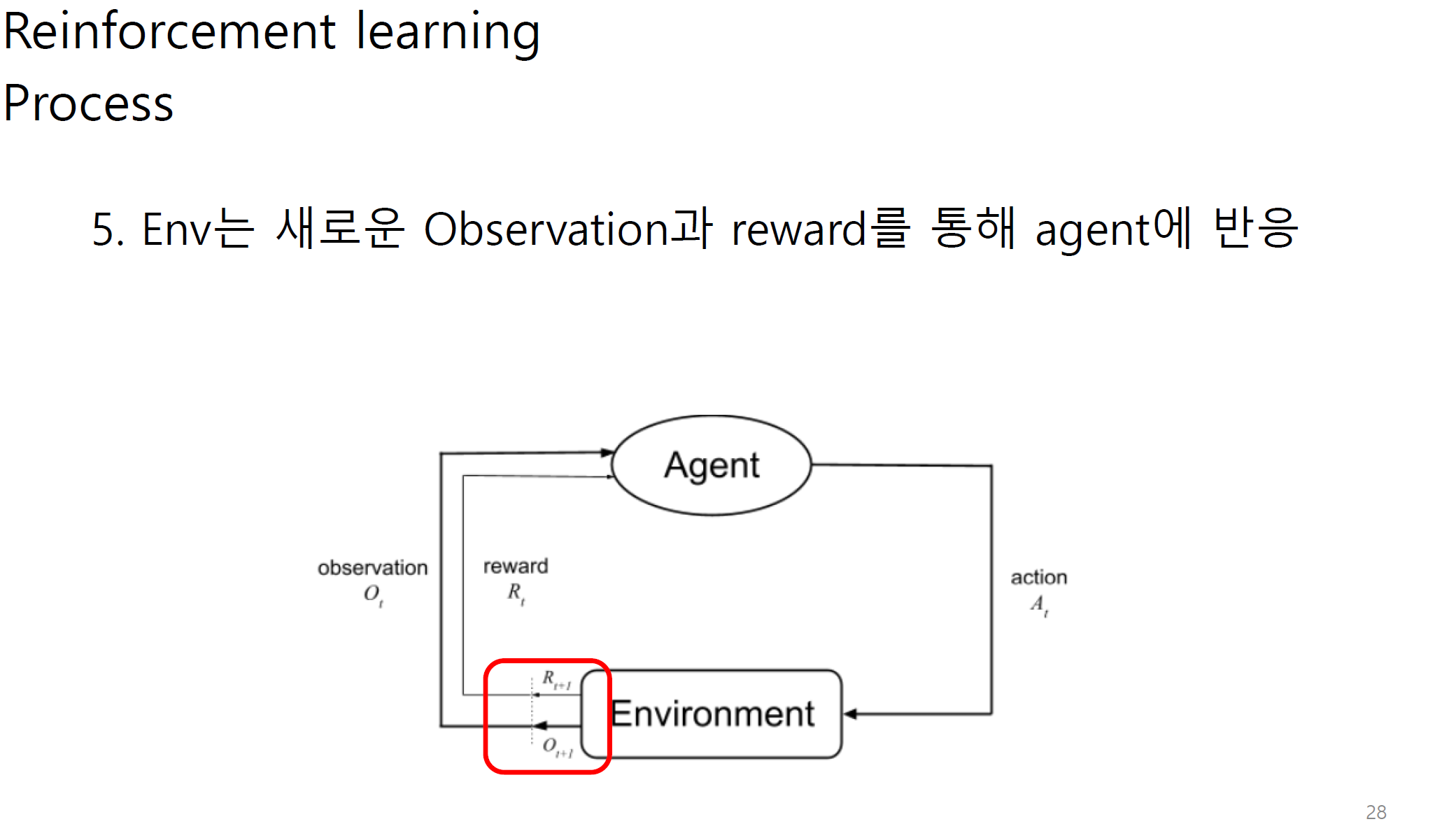
s_t+1은 결국에 observation을 통해 env에 전달된다.


discount factor가 없다면 미래에 받을 reward도 똑같은 가중치로 누적 reward합으로 계산이 될 것이다.
미래에 받을 reward는 사실 학습이 진행되면 될수록 계속해서 변화하는 것인데, 이 변화를 반영하지 않으므로
계속해서 누적 reward의 합이 최대가 되는 방향으로 학습을 진행한다.




위의 코드는 아래 링크에서 더 자세하게 볼 수 있다.
https://goodboychan.github.io/book/GDRL-chapter-2.html
Mathematical foundations of reinforcement learning
그로킹 심층 강화학습 중 2장 내용인 “강화학습의 수학적 기초”에 대한 내용입니다.
goodboychan.github.io
'인공지능 > 강화학습' 카테고리의 다른 글
| [심층 강화학습] DDPG(Deep Deterministic Policy Gradient) (0) | 2024.02.27 |
|---|---|
| [그로킹 심층 강화학습] - ch3. 순간 목표와 장기 목표 간의 균형(벨만 기대 방정식, 벨만 최적 방정식) (3) | 2024.02.08 |

