Abstract
sequence modeling
시퀀스 데이터 모델링은 어떠한 시퀀스를 가지는 데이터로 부터 또 다른 시퀀스를 처리하는 데티터를 생성하는 tasK이다. 대표적인 예로는 기계 번역, 챗봇 등이 있다. 대부분 시퀀스 모델링은 RNN, CNN을 이용하였다. 이 모델들의 문제점은 모든 데이터를 한 번에 처리하는 것이 아니라 시퀀스 순서에 따라서 순차적으로 입력을 넣어준다. 이를 보완하기 위해서 Sequence to Sequence 모델을 사용한다.
Sequence to Sequence model

사진 출처 : https://yjjo.tistory.com/35
기계번역 task를 예시로 seq2seq모델을 설명해보자면 인코더, 디코더 구조로 이루어져 있으며 인코더의 최종 출력(소스 문장의 최종 히든 스테이트)이 디코더의 입력으로 들어가 문장번역을 수행한다. 각 타임 시퀀스 순서로 데이터가 입력되고, 이전 데이터를 요약한 정보인 히든 스테이트가 다음 데이터를 예측하기 위한 정보로 사용된다.
Sequence to Sequence model의 한계
사진 출처 : https://techblog-history-younghunjo1.tistory.com/493
하지만 이 모델에는 한계점이 존재한다. 시퀀스 데이터가 입력되면 요약정보인 히든 스테이트를 만들게 되는데 이 히든 스테이트 벡터 길이가 모두 동일한 길이의 벡터로 만들어진다. 위의 그림을 보면 최종 히든 스테이트 길이가 4개의 벡터로 고정 되어있다. 문장의 길이가 짧은 ‘I like an apple’ 문장은 4개의 단어 벡터로 이루어졌고 이 4개의 단어 벡터를 최종 히든 스테이트의 벡터로 요약하면 문장에 대한 정보가 잘 담길 것이다. 하지만 그림의 세 번째 문장처럼 길이가 긴 문장은 4개의 히든 스테이트 벡터로 요약한다면 문장에 대한 정보가 잘 담기지 않을 것이다. 그래서 이 모델을 보완한 Sequence to Sequence with Attention 모델이 있다.
Sequence to Sequence with Attention model
Sequence to Sequence with Attention model은 인코더에서 각각의 시퀀스에 가중치를 준 형식으로 전체 시퀀스 입력을 가지고 있다. 시퀀스 순서에 따라서 순차적으로 입력을 넣어주는 것이 아닌 전체 시퀀스 입력을 가지고 있다.
이 부분이 시퀀스 디코더의 각 시퀀스 별로 인코더의 각각의 시퀀스를 가중치를 주어서 요약한 컨텍스트 벡터를 만든다. 디코더는 히든 스테이트 S^<0>와 인코더의 전체 시퀀스를 가진 컨텍스트 벡터를 입력으로 받고 타임 시퀀스에 따라서 갱신하면서 출력단어를 생성한다. 각각의 입력에 대한 순서 정보를 먼저 정렬 시킨 후에 이것을 반복적인 입력으로 넣어 히든 스테이트들을 갱신시키는 방법으로 동작한다. 하지만 시퀀스 길이 만큼 네트워크에 입력을 넣으므로 병렬적인 처리가 어렵다. 이러한 점은 메모리 및 속도 측면에서 비효율적이라고 지적한다.
이 논문에서 설명하고자 하는 모델은 Transformer 모델이다. 이 모델은 순차적으로 시퀀스를 처리하는 것이 아니라 전체 시퀀스를 한 번에 모두 처리한다. 인코더, 디코더 안에 RNN 모델이 아닌 Attention 레이어를 쌓는다. 이 Attention 메커니즘을 사용하게 되면 순차적으로 시퀀스를 처리할필요가 없어지고 완전히 병렬적으로 시퀀스 데이터를 처리할 수 있다. Attention 메커니즘은 매번 출력 단어를 생성할 때, 소스 문장의 정보 중에서 어떤 정보에 집중할 것인지에 대해 가중치를 부여한다.
Model Architecture
Transformer의 모델은 인코더 , 디코더 구조이며 내부에는 self-attention과 fully-connected layer로 구성되어있다. 인코더는6개의 동일한 레이어로 구성 되어있고, 각 레이어에는 2개의 서브 레이어가 있다. 첫 번째 서브 레이어는 Multi-head-Attention 레이어, 두 번째 서브 레이어는 fully-connected layer이다. 두 개의 서브 레이어마다 layer normalizationd 후에 residual connection을 사용한다. Residual-connection을 사용하기 위해서는 입력과 서브레이어를 통과한 출력의 크기, 즉 임 베딩 레이어의 출력을 맞추어주어야 한다. 디코더도 동일하게 6개의 레이어로 구성되어있다. 6번쨰 인코더의 출력이 6개의 디코더 입력으로 각각 들어가게 된다.
Transformer는 Recurrennt model을 전혀 사용하지 않고 오직 Attention 메커니즘만을 사용하기 때문에 시퀀스 정보를 표현할 수 없다. 그래서 ‘Positional encoding’를 이용해 시퀀스 정보를 데이터에 추가해준다. Positional encoding이 적용된 임베딩은 ‘Self-head-Attnetion’을 진행한다. 입력 문장에 있는 각각의 단어가 다른 어떤 단어와 높은 연관성을 가지는지에 대한 정보를 학습한다. 예를 들어서, ‘I like an apple’ 이라는 문장에서 I와 like 높은 연관성을 가지는 것처럼 말이다. Attention은 입력 문장 전체의 문맥정보 (context vector)를 잘 학습하도록 만든다.
Multi-head-Attention
Mulit-head-attention 레이어는 self-head-attention레이어를 여러개 수행한 것이다. 모델에서 3개의 Mulit-head-attention 레이어가 존재한다. 인코더에 있는 1번째 Multi-head-Attention은 번역할 소스 문장을 Positional encoding을 거치고 행렬로 입력 받는다. 이 레이어에서는 소스 문장의 단어벡터 끼리의 유사도를 구한다. 그리고 feedforward layer를 통과한 후 출력 값이 디코더의 Mulit-head-attention layer의 입력이 된다.
디코더의 Multi-head-attention 레이어는 2개이다. 디코더의 첫 번째 Mulit-head-attention layer는 소스 문장이 번역된 임베딩 문장을 행렬로 입력을 받고, 이 문장 행렬로 부터 각 시점의 단어를 예측하도록 훈련한다. 이때 디코더에서는 현재 시점의 예측에서 현재 시점보다 미래에 있는 단어들을 참고하지 못하도록 미래에 단어들을 마스킹 한다. 2번째 Multi-head-attention 레이어의 입력으로 들어간다.
디코더의 2번째 Multi-head-attention 레이어는 디코더의 1번째 레이어에서 Query를 입력 받고 Key와 value는 인코더의 출력에서 가져온다. 이는 디코더의 모든 위치의 벡터들로 인코더의 모든 위치 값들을 참조 하면서 디코더의 시퀀스 벡터들이 인코더의 시퀀스 벡터들과 어떠한 유사도를 가지는 지를 학습한다.
Self-Attention Mechanism
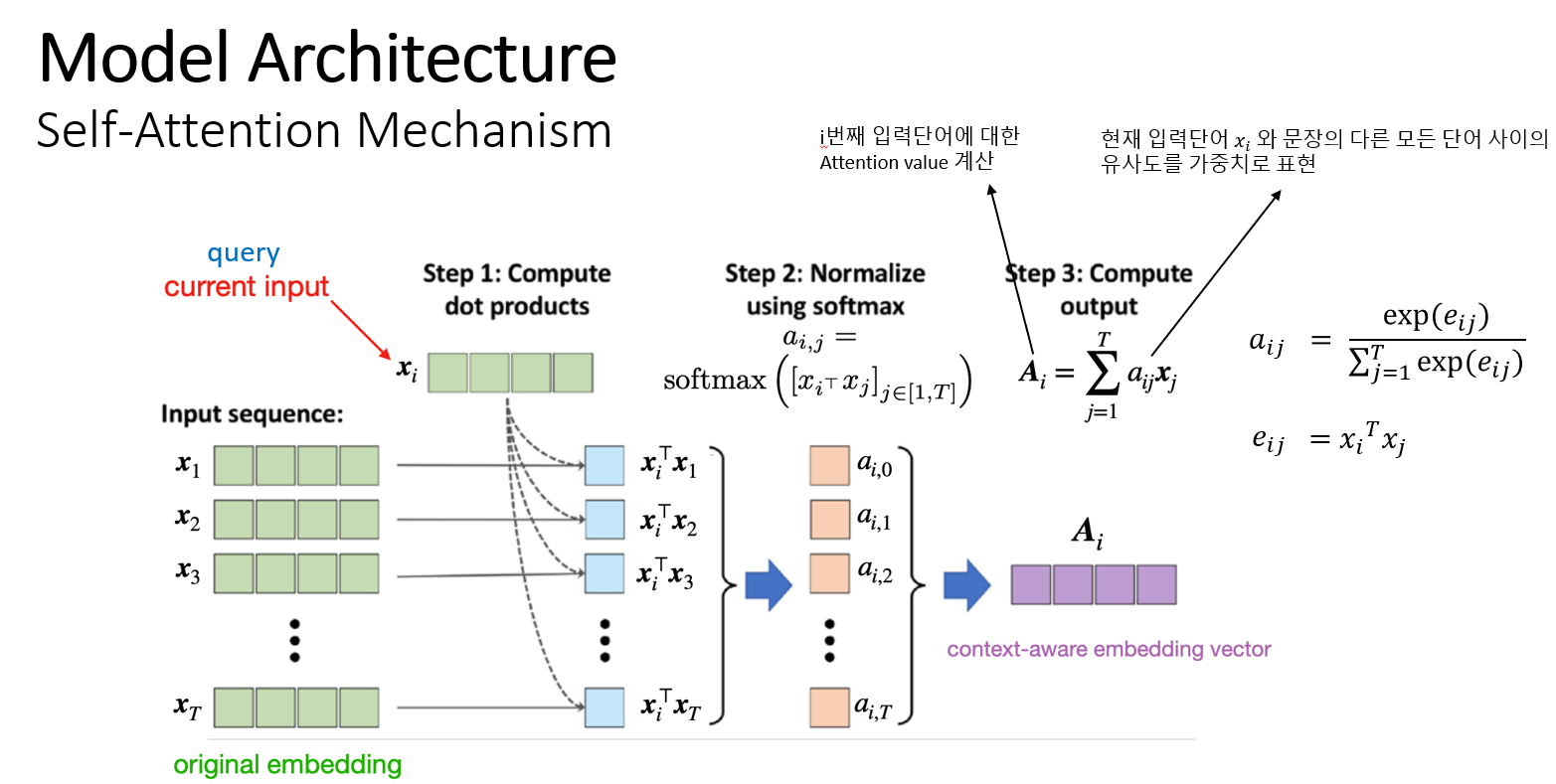
Multi-head-Attention레이어를 이해하기 위해서는 Self-Attention 메커니즘을 알아야 한다. 먼저 초록색으로 나타낸 블럭은 입력 시퀀스 X이다. 이 입력 시퀀스는 문장으로 생각할 수 있다. x1, x2, … x^T는 문장에서 각각 단어를 나타내는 벡터이다. 비교 대상이 되는 단어 벡터를 xi라고 가정하고, 이 xi는 문장의 모든 단어와 유사도를 구한다. 이 값이 어텐션 가중치이다. 그리고 softmax 함수를 통해 0~1 사이의 값으로 어텐션 가중치를 정규화한다.
xi가 x1부터 x^T까지 문장의 모든 단어 벡터들과 얼마나 유사한지에 대해서 어텐션 가중치를 부여한다. 벡터 A는 xi가 문장에서 다른 어떤 단어와 유사한지 하나의 컨텍스트 벡터로 요약한다. A는 문장에서의 단어가 T개 있으므로 A1~A^T 벡터를 쌓은 행렬 형태로 만들어진다. 하지만 이 메커니즘은 학습 가능한 파라미터가 없다.
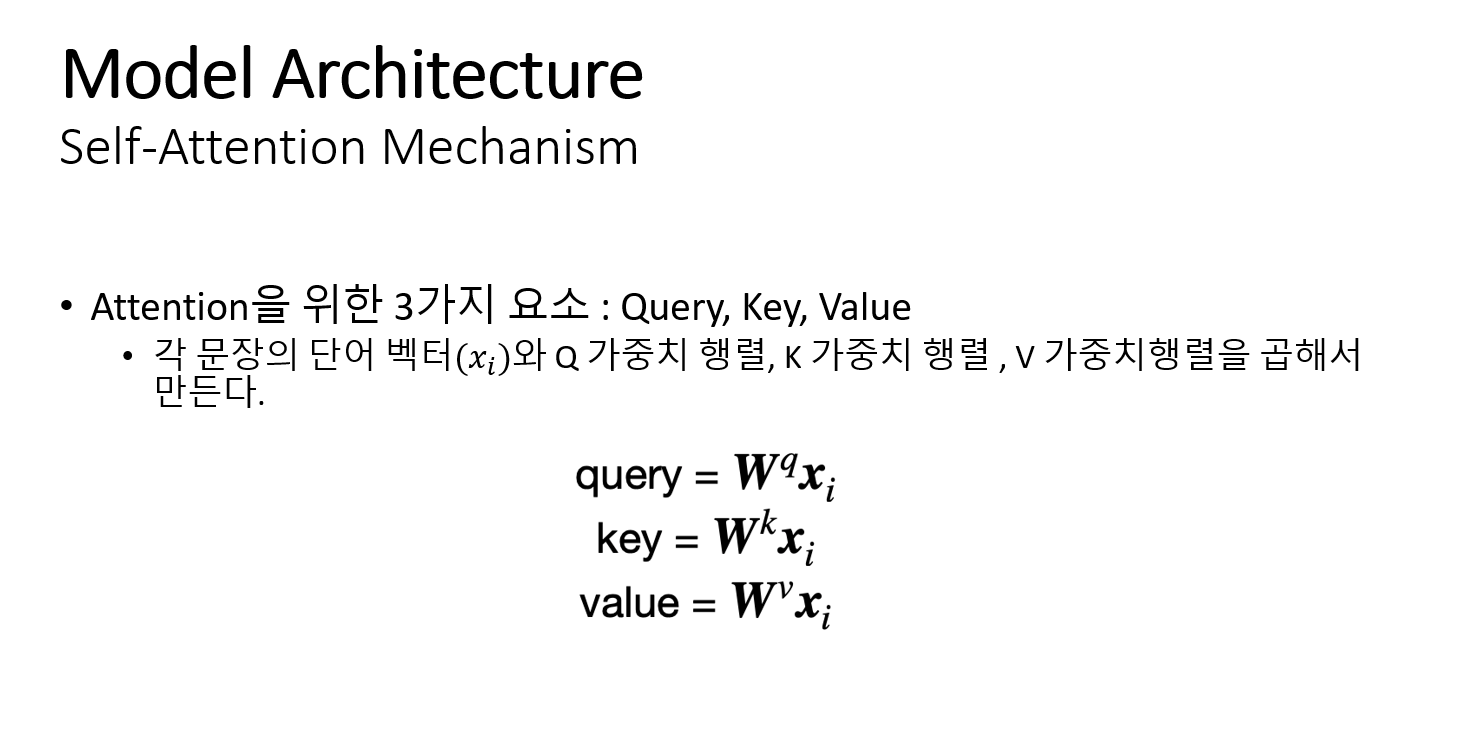
파라미터가 없으면 학습 할 수가 없으므로 입력 시퀀스 임베딩(각 문장의 단어벡터들)과 곱해지는 3개의 훈련 가능한 가중치 행렬을 만들어 학습할 수 있게 한다. 3가지 가중치 행렬들은 역전파로 업데이트 할 수 있다.
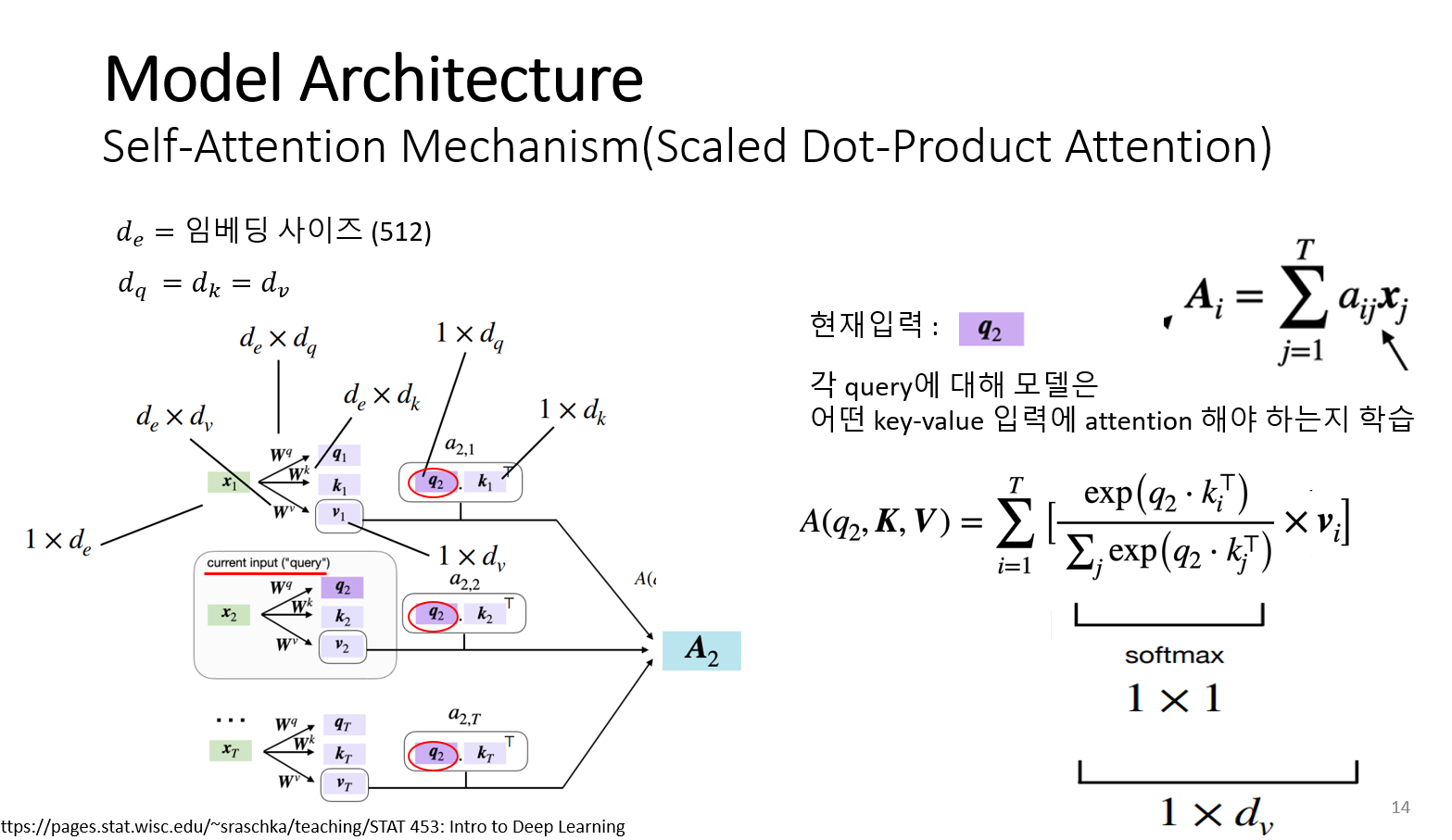
Self-Attention-Mechanism을 실제 차원으로 표현하면 위의 그림과 같다. 논문에서는 임베딩 벡터의 사이즈가 512이다. 문장의 각 단어 벡터들은 1 x 임베딩 벡터 사이즈(512)로 열벡터로 나타낸다. 단어 벡터들은 가중치 행렬(query 가중치 행렬, key 가중치 행렬, value 가중치 행렬)들과 곱해져서 query, key, value를 만든다. 가중치 행렬(query 가중치 행렬, key 가중치 행렬, value 가중치 행렬)는 논문에서는 크기가 모두 같다고 설정한다.
가중치 행렬들의 차원은 임베딩 사이즈 x query 사이즈 , 임베딩 사이즈 x key 사이즈 , 임베딩 사이즈 x value 사이즈 이다. 단어 벡터와 가중치 행렬들이 곱해져서 만들어진 query, key , value 차원은 1 x query 사이즈, 1 x key 사이즈, 1 x value 사이즈이다. Query는 비교 대상이 되는 벡터라 query는 모두 동일하다. 위의 그림에서 현재 입력단어 q2와 문장의 다른 모든 단어(Key) 사이의 유사도를 내적해서 어텐션 가중치로 표현한다.
구한 어텐션 가중치는 소프트 맥스를 통해 정규화한 가중치를 주고 이 값에 value 벡터를 곱한 후 모두 더한다. 이 값은 Attention value가 된다. A(q2, K, V)는 문장의 두 번째 단어 x2에 대한 Attention value가 된다. Attention value는 (1 x value 사이즈) 차원을 가지는 벡터이다.
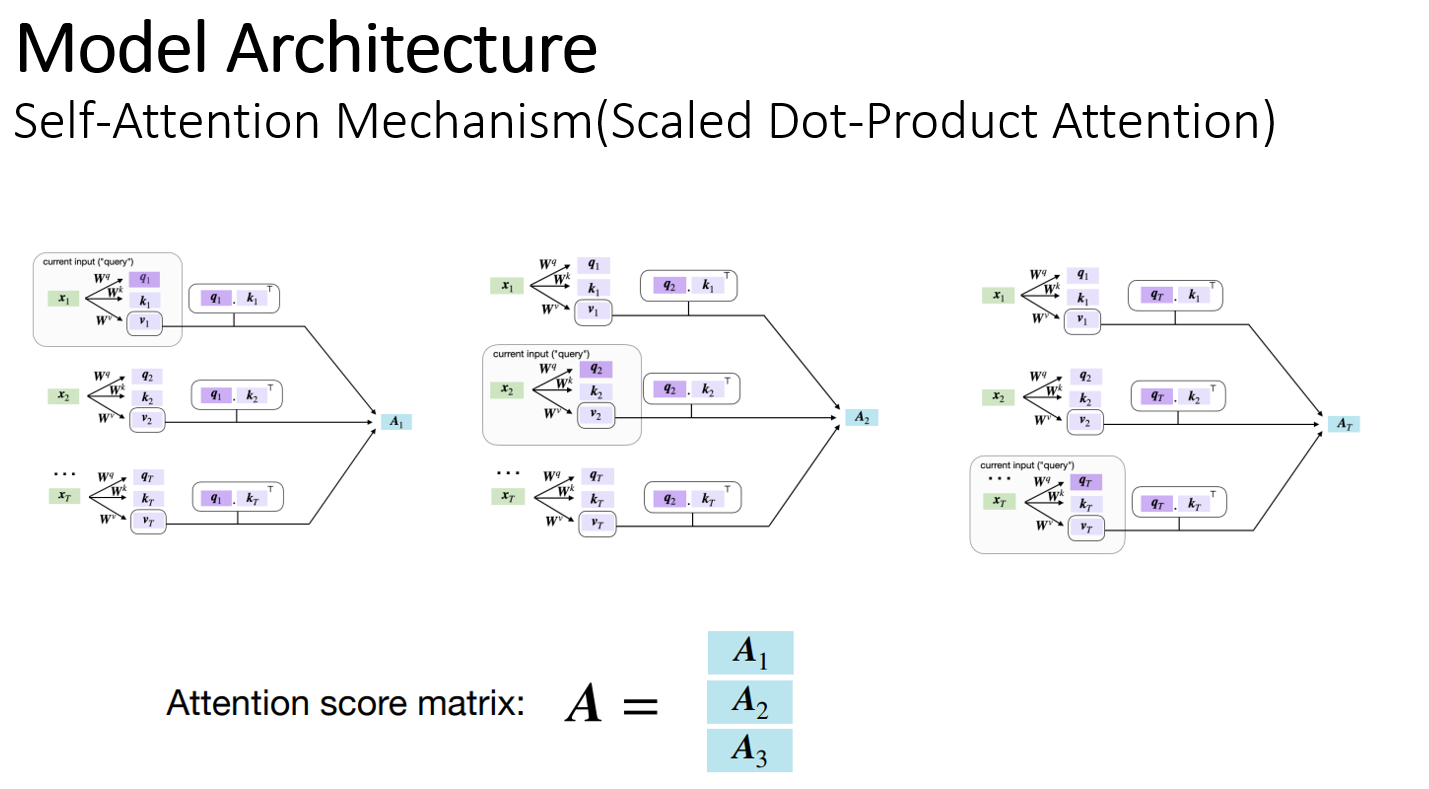
문장의 모든 입력 벡터 (X1~XT)에 대해서 위의 과정을 반복한다. Attention 스코어 행렬을 구하는 과정은 병렬적으로 가능하다. 각 단어 벡터에 대한 어텐션 가중치를 계산 후 Attention 스코어 행렬을 얻는다.

실제 단어 벡터를 행렬로 나타내서 ( T(입력 시퀀스 사이즈) x 임베딩 사이즈 (512) ) 행렬로 나타내서 병렬적으로 query,key 사이의 유사도를 계산 후 Value 값을 곱해서 어텐션 value를 만든다. 최종적인 출력 차원은 (T x value size) 이다.
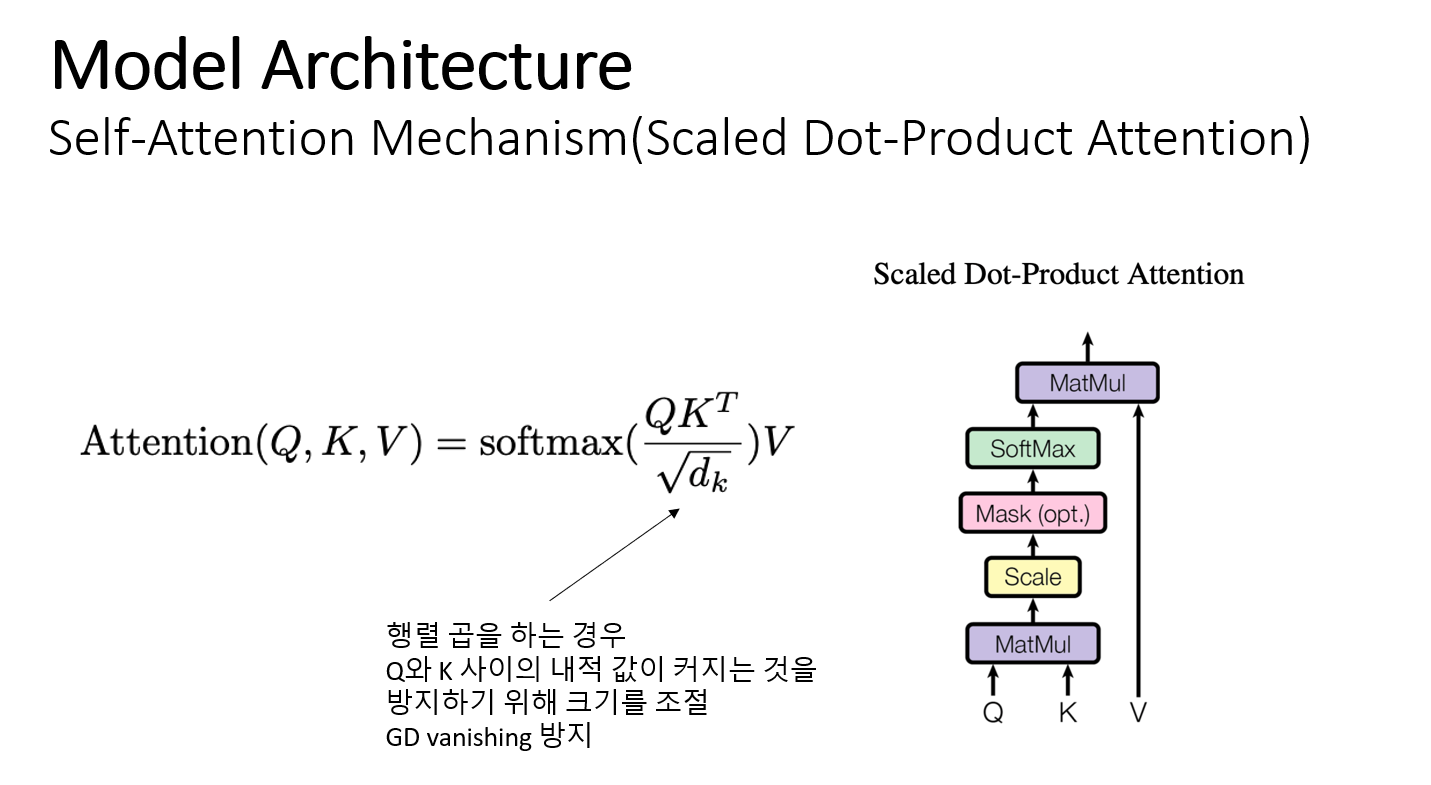
Self-attention 메커니즘은 왼쪽의 수식으로 정리할 수 있다. Query와 key를 행렬곱 할 때 루트 key의 차원으로 나눠 주게 되는데 이는 Query와 key를 행렬곱한 값의 크기가 커지는 것을 조절한다.
Multi-head-Attention Mechanism
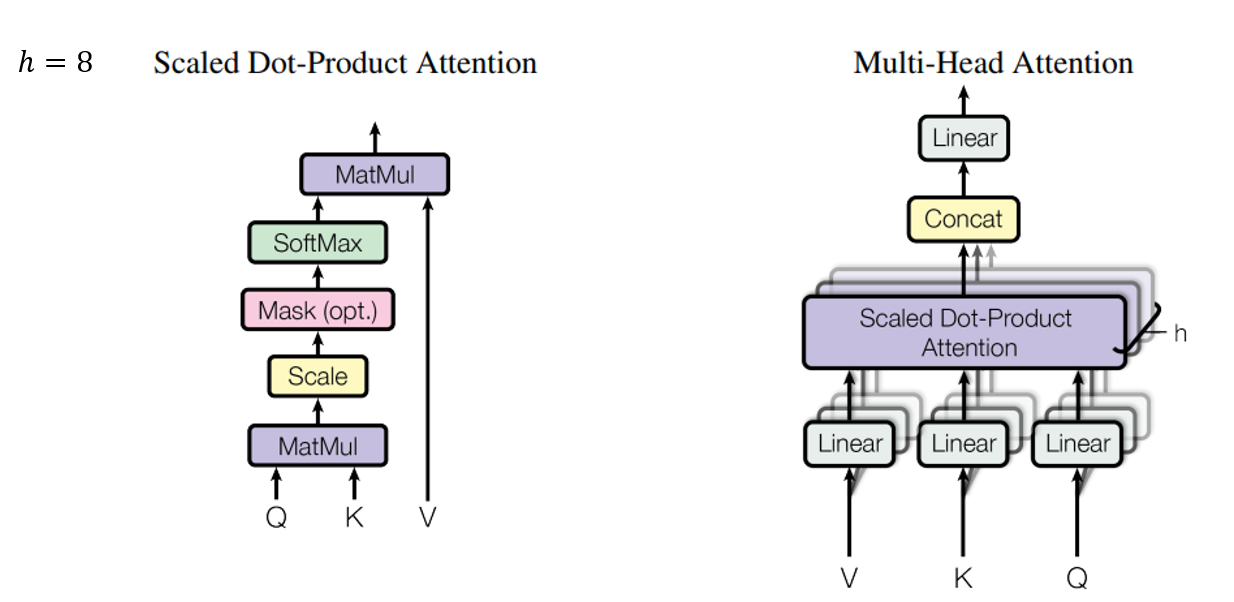
Multi-head-Attention은 Self-Attention 메커니즘을 헤드 개수만큼 반복한다. 논문에서는 헤드 개수가 8개이며 Self-Attention 메커니즘을 8번 반복한다. 그렇게 되면 어텐션 값이 8개가 나오고 이 것을 합쳐서 linear layer를 통과시키면 최종적인 출력이 된다.
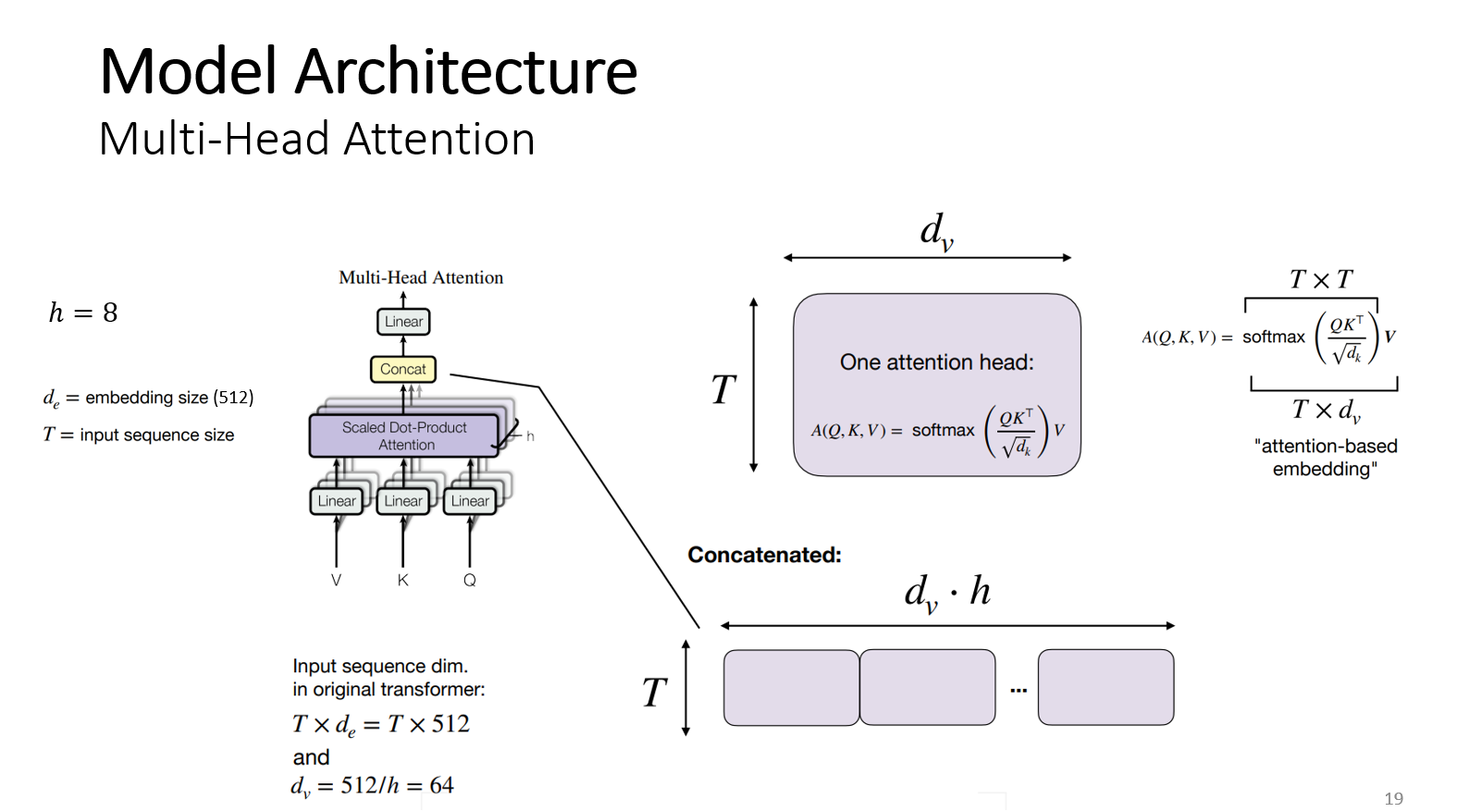
헤드의 개수(h) 만큼 가중치 행렬 (query 가중치 행렬 , key 가중치 행렬, value 가중치 행렬)을 만든다. 논문에서는 헤드의 개수가 8개 이므로 각각의 가중치 행렬을 8개씩 만들고 입력 단어 벡터와 가중치 행렬을 곱해서 8개의 query, key, value를 만든다. 모델이 각 헤드에 대해 다르게 시퀀스의 다른 부분에 주의를 기울이게 한다. ( T x value 사이즈 )가 h번 반복하고 이것을 concat하면 T x 임베딩 사이즈 (512) 차원을 얻게 된다. 어텐션을 8번 반복 할 때 마다 매번 다른 8개의 가중치 행렬로 수행한다.
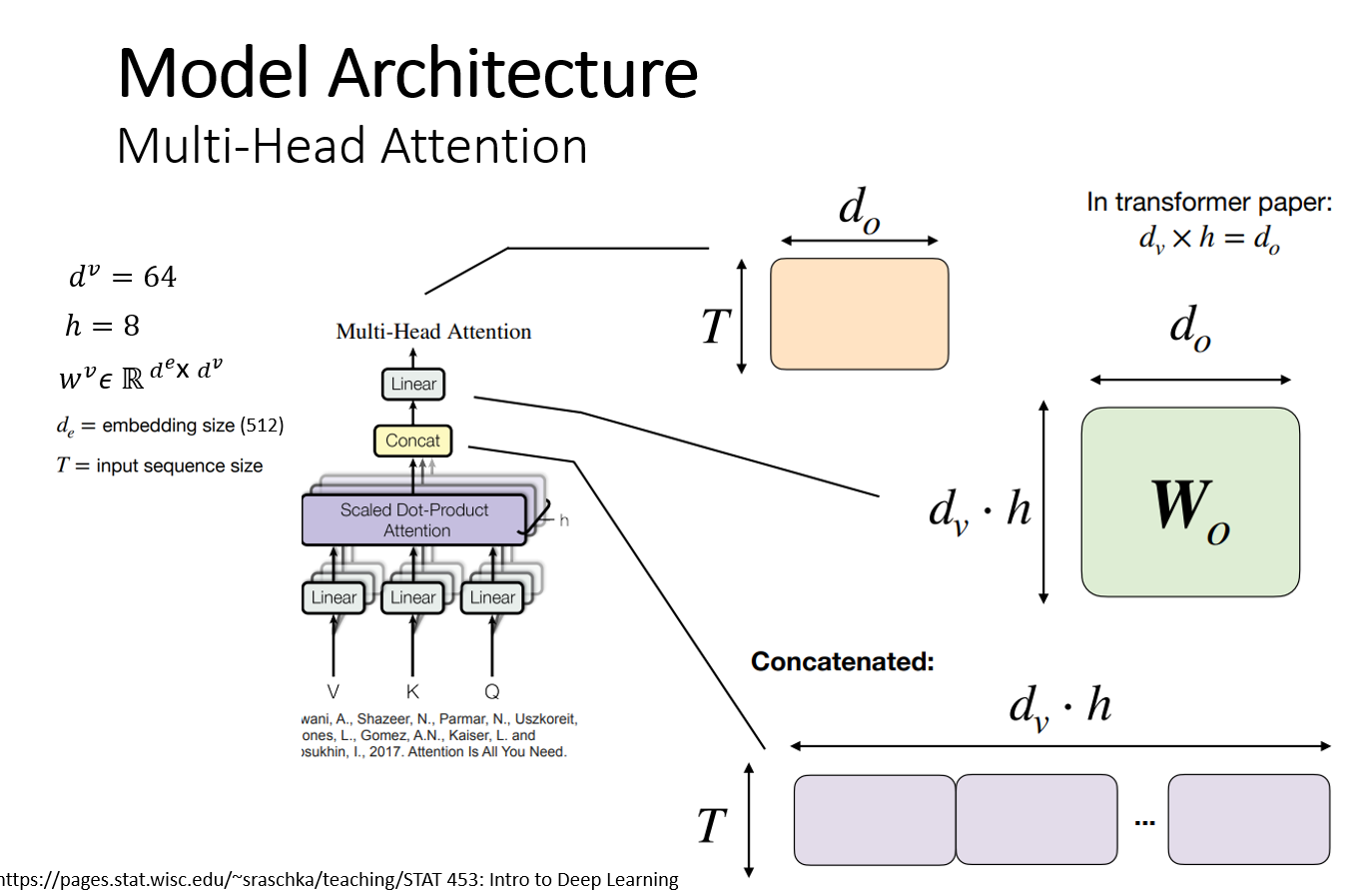
헤드의 개수가 8개이고 8번의 Multi-head-attention을 병렬로 여러 번 적용하고 결과를 concat해서(T x (value size x 8)) 각각 fully-connected layer( (value size x 8) x d0) 에 연결해서 배치한다. Do차원은 512로 최종적으로 T X d0 행렬은 512 x 512 차원을 가진다. 입력 차원도 512 x 512 , 출력 차원도 512 x 512이며 입력 차원과 출력 차원이 같아야 Residual connection을 수행할 수 있다.
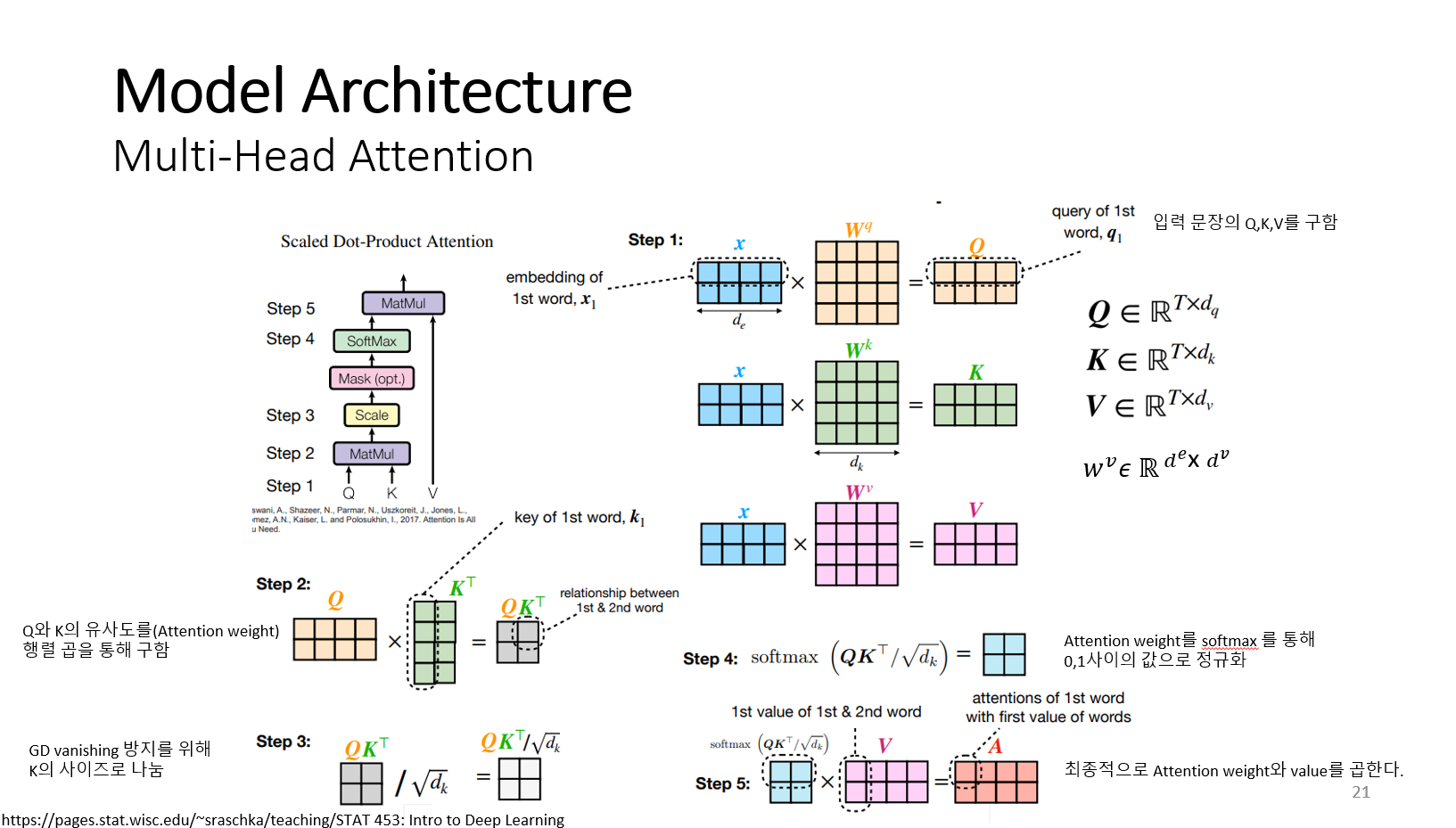
Self-head attention 메커니즘을 정리하자면 다음 그림과 같다. X 행렬은 문장의 모든 단어 벡터들을 표현한다.
첫 번째 단계에서 X 행렬에 query 가중치 행렬(wq)을 곱한다. X 행렬은 문장의 모든 단어 벡터를 표현한 것이다. 이 과정은 단어 벡터 x 로 부터 query(query 행렬)을 생성한다. 논문에서는 Query, key, value 행렬의 차원은 모두 같다고 가정한다.
두 번째 단계에서 query와 key 사이의 행렬곱을 수행해서 단어 간의 관계를 파악한다.
세 번째 단계에서 query와 Key의 사이즈로 크기를 조절해서 softmax가 saturation 되는 것을 방지한다. Softmax 값이 0이 되면 기울기가 점차 작아져서 훈련을 할 수 없기 때문이다.
네 번째 단계에서 어텐션 가중치를 softmax를 통해 0 과 1 사이의 값으로 정규화 한다. 다섯 번째 단계에서 정규화된 값(어텐션 가중치)과 value 값을 곱해서 Attention 스코어 행렬을 구한다. 이 행렬의 첫 번째 행은 문장의 첫 번째 단어와 다른 모든 단어 관계를 포함한다.
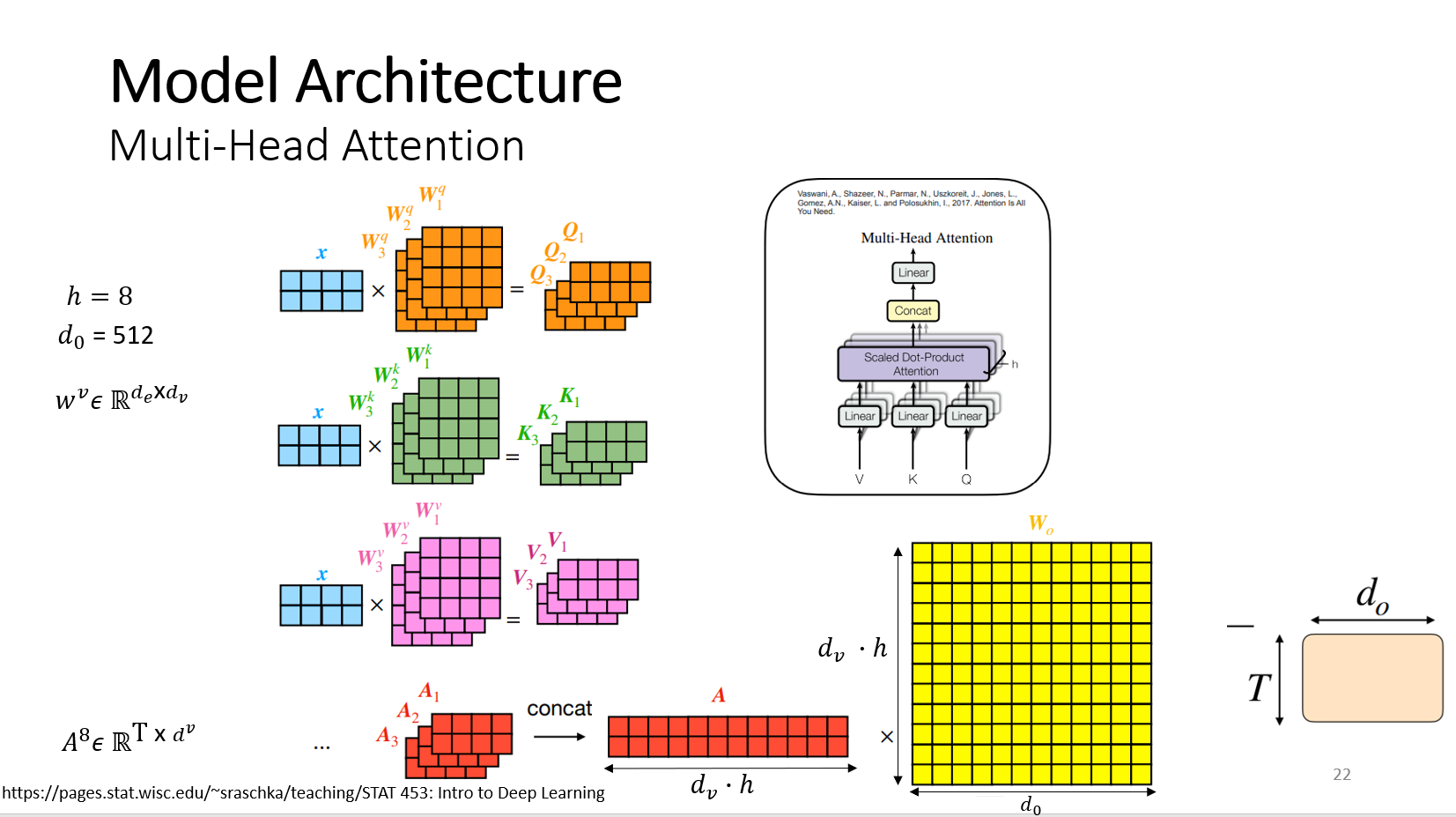
Multi-head Attention 메커니즘은 정리하자면 위의 그림과 같다. 헤드의 개수가 8개라고 가정하면 가중치 행렬들이 8개씩 만들어진다. 이 가중치 행렬과 단어벡터 행렬 X와 곱해 query, key , value를 각각 8개씩 만든다. 이 과정은 병렬적으로 수행 가능하다. Attention score 행렬이 8개가 만들어지고 linear layer에 통과 시키기 위해서 concat 후 이것을 (value size x h) x 512 차원 행렬과 행렬곱을 수행한다.
Masked Multi-head-Attention
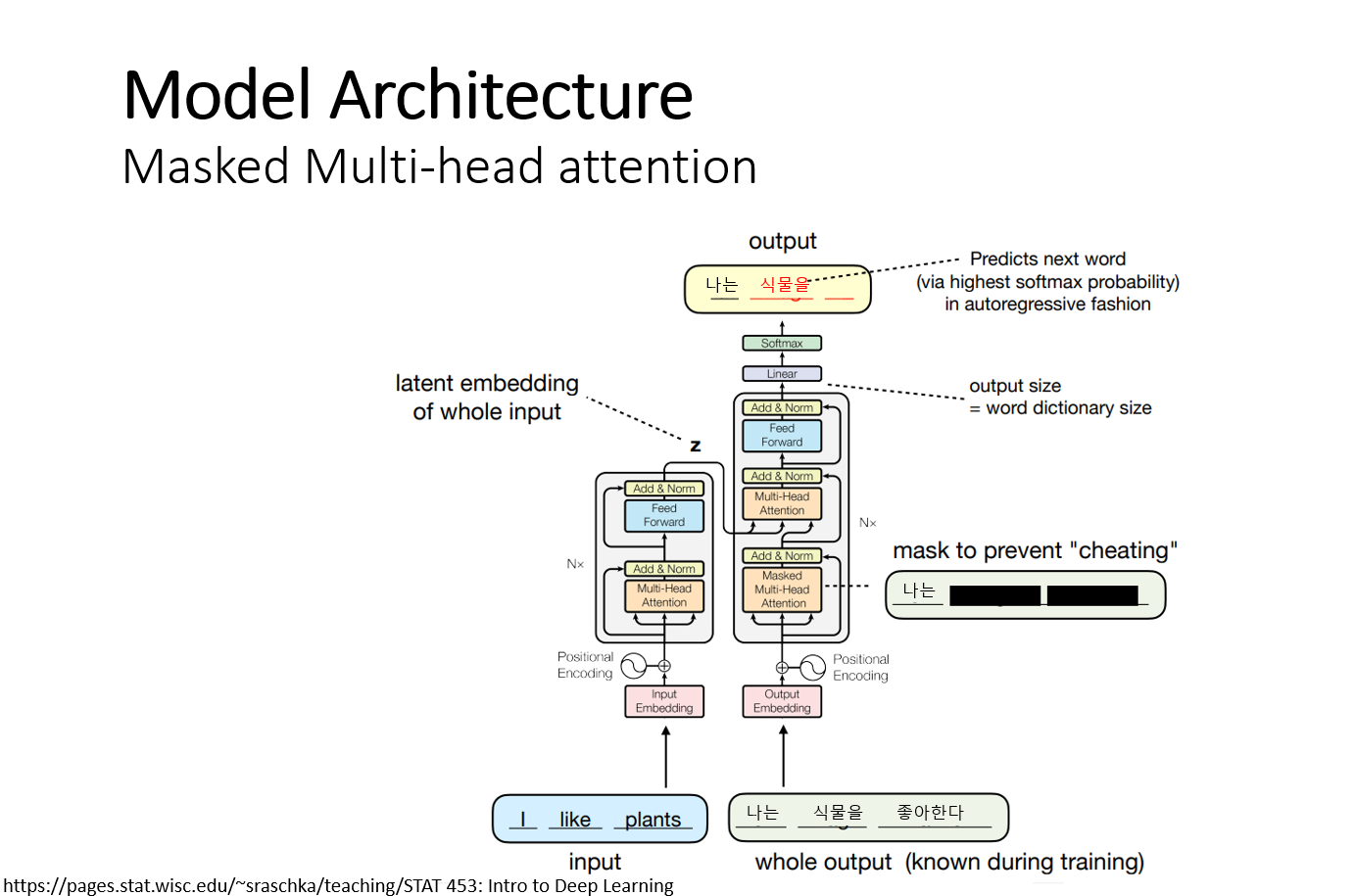
디코더의 1번째 Multi-head attention 레이어는 시퀀스의 일부 입력에 마스킹을 하는 점을 제외하면 Multi-head-Attention 메커니즘과 같은 개념이다. 예시로 3개의 단어로 구성된 I like plants 문장이 있고 현재 1개의 단어(나는)는 생성이 완료되었고 2번째 단어(식물을)를 생성하고 있다고 가정한다. Ouputs embedding에는 이미 식물을, 좋아한다 라는 단어가 존재하고 이 단어들을 마스킹 하는 과정이다. 훈련을 할 때에는 마스킹 없이 한 번에 한 단어씩 생성하지만 테스트 할 때는 아직 생성되지 않은 단어에 대해서 마스킹을 해주어야 한다.
Feed-Forward Networks

Transformer 모델 구조에서 인코더 6개, 디코더 6개로 구성되어있고, Feed-Forward layer에서 가중치는 6개의 레이어마다 다르게 학습된다.
Positional Encoding
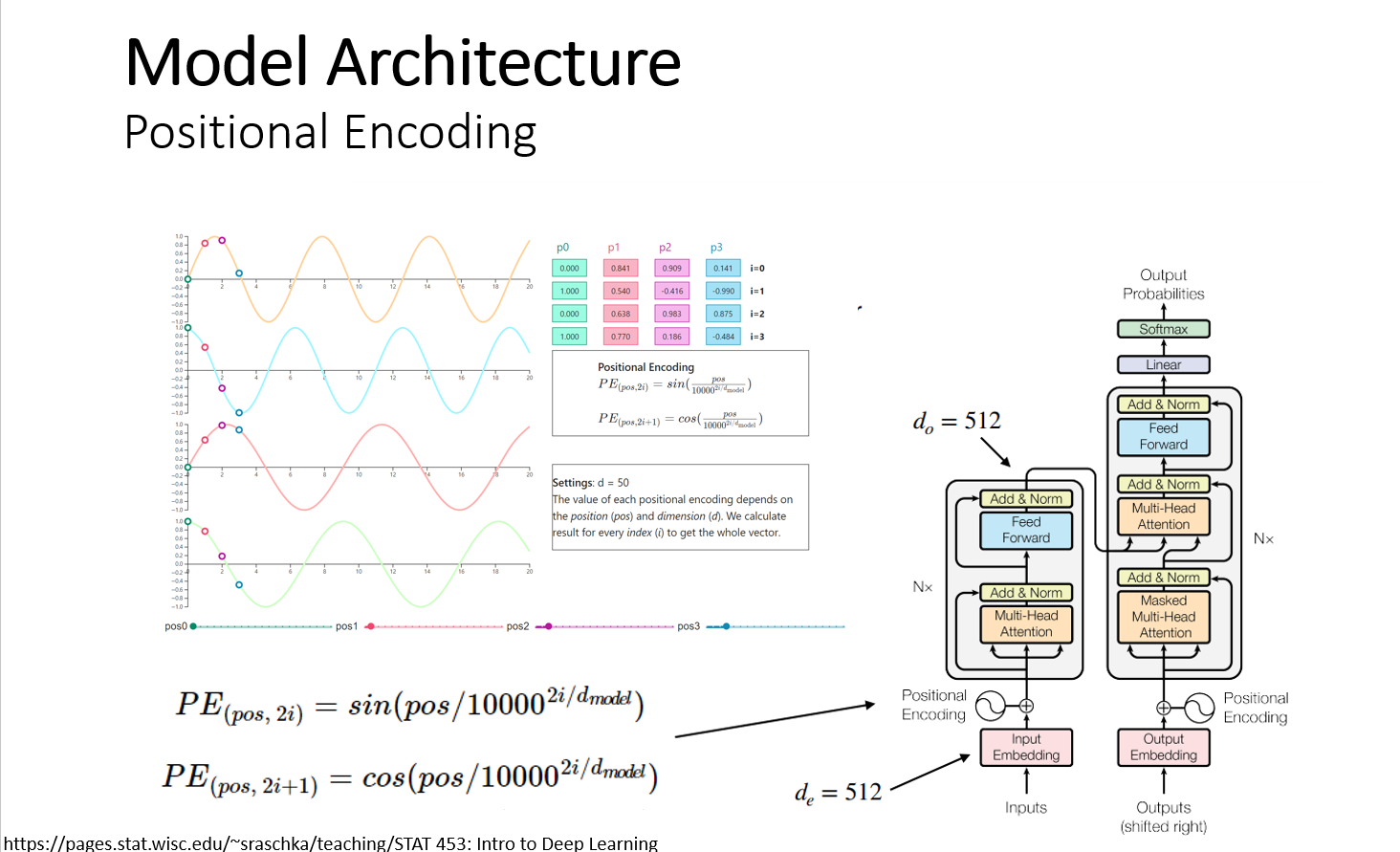
Attention 메커니즘은 기존의 RNN의 모델과는 다르게 순서정보가 없다. 단어가 문장에서 어디에 위치하는 지 알 수가 없으므로 각 문장의 단어의 순서 정보를 포함해주어야 한다. Positional encoding을 이용해서 단어의 임베딩 벡터에 순서정보를 더해 준다. Positional encoding은 정현파 신호(cos, sin)를 이용해서 문장에서 각 단어의 위치에 따라 다른 결과를 얻게 한다.
Why Self-Attention
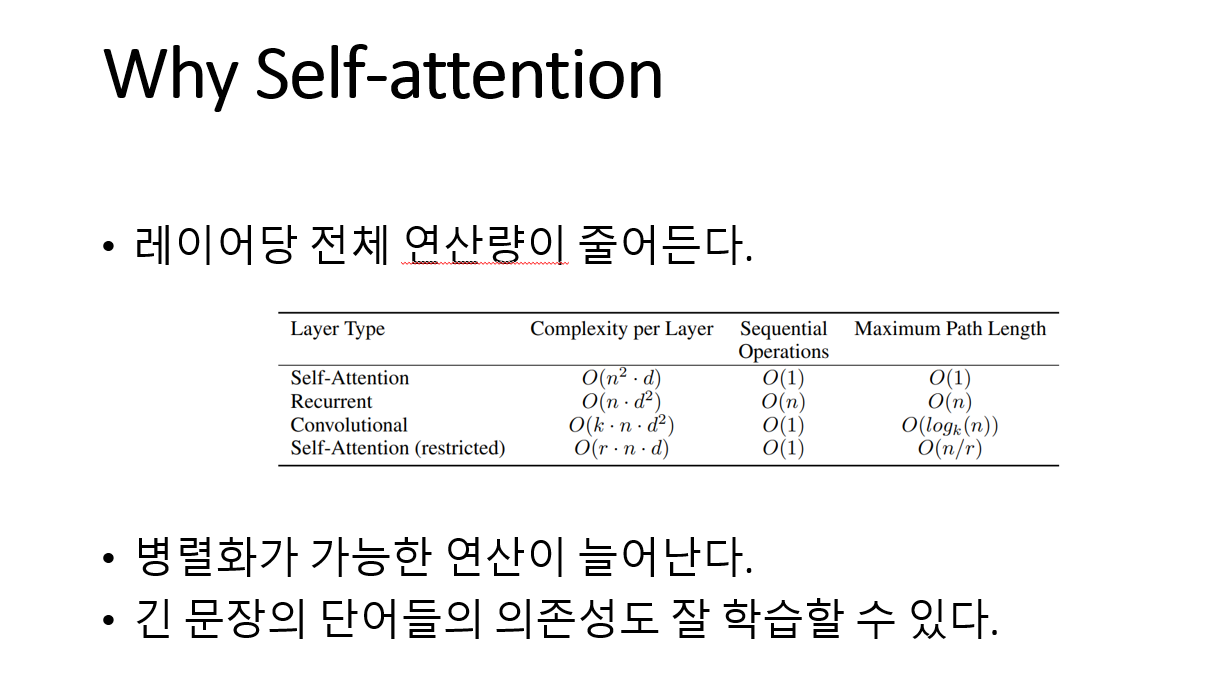
왜 self-attention이 RNN이나 CNN 보다 좋을까? 논문에서는 3가지로 나누어 설명한다.
첫 번째, 레이어당 전체 연산량이 줄어든다. 첫 번째, 표에서 self-attention과 RNN을 비교해 보면 시퀀스 길이 N이 respresentation dimensionality(d)보다 작아야 복잡도가 self-attention이 RNN보다 더 낮아진다. 보통 n이 d보다 작은 경우가 대부분이여서 self-attention이 복잡도가 더 작다고 말한다.
두 번째, 병렬화가 가능한 연산이 늘어난다. RNN은 Input을 순차적으로 입력 받아서 총 n번 RNN cell을 거치게 되고, Self-attention layer는 input의 모든 위치 값들을 연결하여 한 번에 처리 가능하다. 따라서 Sequenctial operations이 O(1)을 가지고, 이는 병렬 시스템에서 유리하게 작용한다.
세 번째, 긴 문장의 단어들의 의존성을 잘 학습할 수 있다. 위치상 멀리 떨어져 있는 단어들 간의 의존성을 학습 하기 위해서는 length of paths가 큰 영향을 미친다. Self-attention은 각 단어 토큰들을 모든 토큰 들과 참조하여 유사도 정보를 더해서 구해주기 때문에 Maximum path length를 O(1)이라고 볼 수 있다. 따라서 긴 문장의 의존성을 더 쉽게 학습할 수 있는 장점을 가진다.
결론적으로 self-attention 메커니즘은 전체 문장을 한 번에 참조하여 학습할 수 있는 것이 큰 장점이다.
참고 자료
https://sebastianraschka.com/pdf/lecture-notes/stat453ss21/L19_seq2seq_rnn-transformers__slides.pdf
https://arxiv.org/abs/1706.03762
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org
https://erdem.pl/2021/05/understanding-positional-encoding-in-transformers
Understanding Positional Encoding in Transformers - Blog by Kemal Erdem
What is positional encoding? As I’ve explained in “Introduction to Attention Mechanism”, attention doesn’t care about the position of the inputs. To fix that problem we have to introduce something called Positional Encoding. This encoding is covere
erdem.pl
https://www.youtube.com/playlist?list=PLTKMiZHVd_2KJtIXOW0zFhFfBaJJilH51
Intro to Deep Learning and Generative Models Course
Deep learning is a field that specializes in discovering and extracting intricate structures in large, unstructured datasets for parameterizing artificial ne...
www.youtube.com
https://sebastianraschka.com/blog/2021/dl-course.html
Introduction to Deep Learning
I just sat down this morning and organized all deep learning related videos I recorded in 2021. I am sure this will be a useful reference for my future self,...
sebastianraschka.com